

Ship, Score, Repeat: Why Continuous Evals Win
CI/CE Pipelines Make AI Products Defensible

Software Synthesis analyses the evolution of software companies in the age of AI - from how they're built and scaled, to how they go to market and create enduring value. You can reach me at akash@earlybird.com.
Gradient Descending Roundtables:
Over the last few weeks we’ve been gathering London’s AI builders for technical roundtables. Now that the series is becoming a fixture in the ecosystem, it deserves a proper name.
“Gradient Descending” felt right—after all, everyone in the room is chasing a lower loss function!
July 30th: MCP Part 2 with David Soria Parra
We’ll be doing one more in August (date TBC), before resuming in full swing in September.
Last week’s Evals roundtable built on the introductory post I wrote two months ago.

The main arguments I made at the time were:
Evals are a continuous process; every change to your AI application (e.g. model, prompt) affects performance and as such you have to measure if performance drops below a baseline (the notion of CI/CE). This is critical for domains where accuracy and other metrics drive most of the value for customers.
As such, the infrastructure to continuously run evals becomes the moat, not the dataset itself. The dataset of ground truth data compiled by subject matter experts is only good if it’s a living dataset that continues to grow over time - to do that, you need to invest in the tooling that makes it as easy as possible to amass this data at scale as you launch new verticals, new enterprise customers, etc.
Judge models (LLM-as-a-judge) is a desirable end state but they require continuous monitoring for drift, and therefore human involvement in evals is realistically never going away
This roundtable certainly wasn’t the last we’ll run on this topic, but we already managed to dissect some of these arguments further.
Founder Responsibility At Seed
Evals are increasingly seen as falling into the remit of the new role of ‘AI PM’ or ‘AI Engineer’, but at the earliest stages there’s no one that knows production-readiness better than the founders or founding engineers.
The founders ought to possess the domain understanding needed to bootstrap the initial ground truth data, before onboarding other team members.
At scale, leading vertical AI application companies have a substantial part of their headcount come from the industry they’re selling to, precisely for the reason that they’ll be able to approximate the founders’ judgment in evals.
In the early days of pre-PMF, though, delegating this responsibility will probably compromise your product’s readiness for deployment.
Riding The Maturity Curve
As you develop your evals dataset, having individuals dedicated to turning these insights into defensibility for your company is key in this new paradigm.
Our Venture Partner Luke Miller, Head of Europe at Baseten, spoke about how many leading AI application companies mature from relying on closed-source third party models to fine-tuning open-source models on their own data.
Evals play a crucial role in enabling this. You could imagine the below sequence:
Keep the paid API model (e.g., GPT-4o) as control and ship an open-source fine-tune behind a feature flag. Every user request is answered by both; the eval gate (judge model + unit tests) decides which answer is served and logs the rest.
For every prompt where the open source model loses (lower accuracy, wrong tone, slower, higher cost), the judge attaches a label (loss_reason = "accuracy").
Bundle the new prompt-answer pairs into a nightly LoRA/SFT job on the OSS model.
Re-run the full golden set; if the OSS fine-tune now beats the API model on both quality and unit cost, automatically increase its traffic share (e.g., 10 % → 30 %).
This fine-tune model does constitute true defensibility, but in AI this only lasts if the company continues iterating on it.
Hybrid (internal tooling + external vendors) prevails
The overarching sentiment was that third party tools like Braintrust and Patronus help with getting off the ground, but none of the tools are a good fit across domains as companies scale.
Anecdotally, we see many companies invest in building their own tooling in-house, including for observability (that’s for another post).
Human Evals > Judge Models
An argument that came up at the Browser Agent roundtable resurfaced at this discussion, which is that human evals should not be sacrificed in favour of LLM-as-a-judge approaches. Whilst human evals can pave the way for judge models to assess the majority of PRs over time, the importance of high-quality human evals, especially for edge cases, was stressed again.
That being said, prompting models to create synthetic datasets to cover edge cases is a viable method that should be used in combination with real logs.
For more reading, check out Hamel Husain’s FAQ.
Data
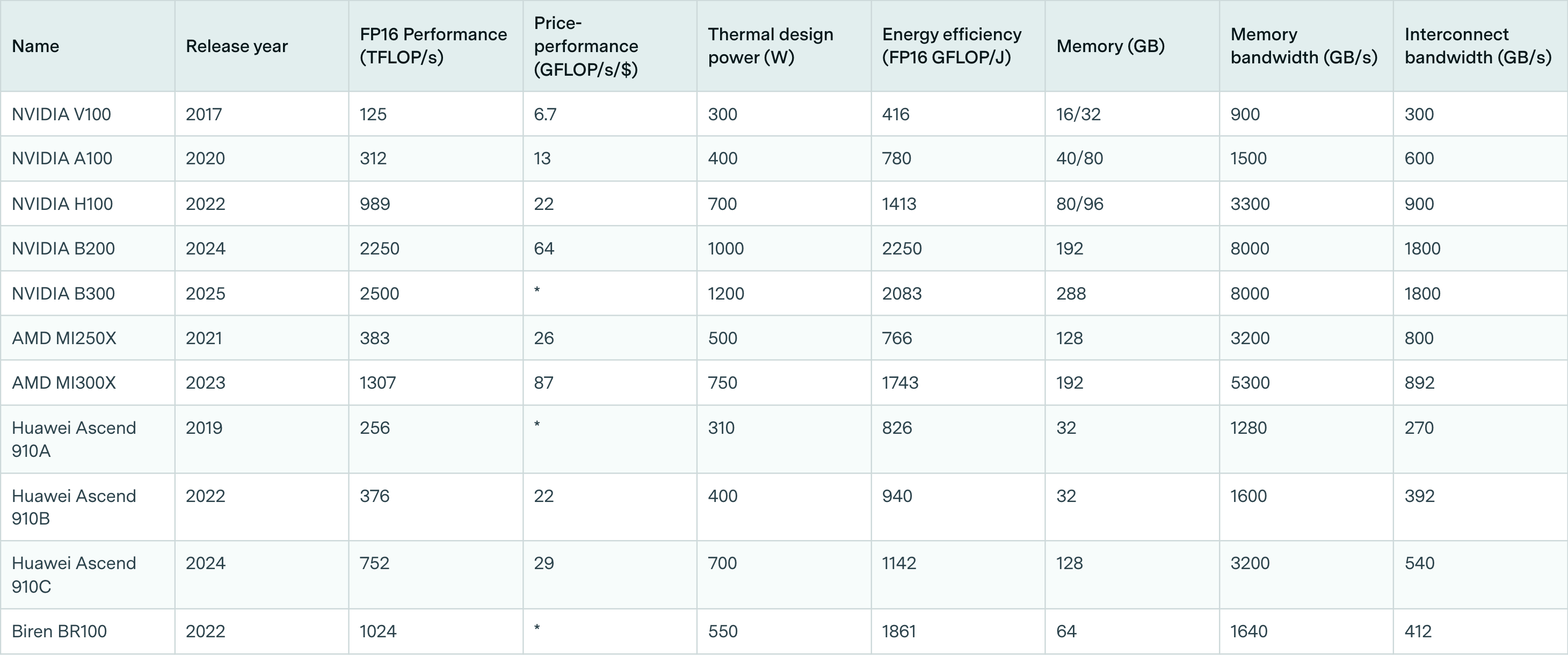
Chinese chips remain years behind leading Nvidia and AMD chips, which is why we’re seeing reports of huge numbers being smuggled in
Cloudflare’s multi-product journey

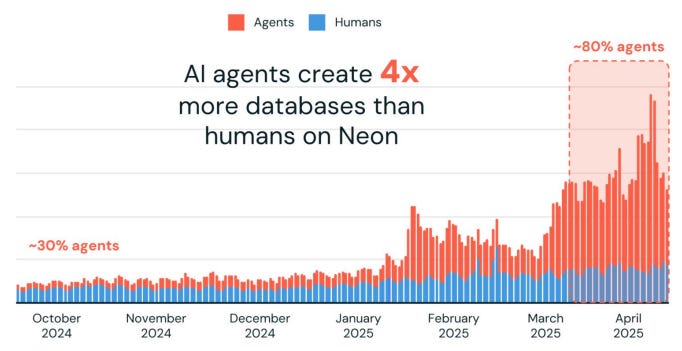
The rotation from humans to agents in software development is accelerating
Reads
Honey, AI Capex is Eating the Economy
Fund Size is Strategy - Extreme Power Law Will Make Portfolio Company Conflicts a Relic of the Past
Google Earnings, Google Flips the Switch on Cloud, Search Notes
Have any feedback? Email me at akash@earlybird.com.
Who authored "You have to be in the water"?