

AI Startup Defensibility: Evals
CI/CD -> CI/CE

Software Synthesis analyses the evolution of software companies in the age of AI - from how they're built and scaled, to how they go to market and create enduring value. You can reach me at akash@earlybird.com.
At the company, we don't strive for complexity, we strive for what works.
The question then is, why is the system so much more complex now? It's because we build really good evaluation systems.
I want the simplest code that ends up having the most impact. The evals were actually really, really critical for us to make a lot of these investments at the company.
That’s Varun Mohan, Windsurf CEO, speaking on the YC podcast.
One of the benefits of running evaluations on coding assistants is that code can be run - this is an objective pass/fail test. Not all domains have this property of objective evaluations, but evals are essential to production-ready AI and are often cited as one of the new (and only) forms of defensibility in the new paradigm of agents.
CI/CD → CI/CE
As CI/CD became a widely followed standard for shipping code, Continuous Integration/Continuous Evaluation may become as important to getting probabilistic AI products into production.
The simplified steps to run evals:
Subject matter experts generate the ‘golden’ dataset of prompts and answers. This dataset can be made up of hundreds of real prompts from users (selected from logs of usage) and answers generated by the experts. This represents the ‘ground-truth’ dataset that future evaluations will be run against.
The golden dataset will include the correct answers to prompts but additional metadata, like tone, completeness, policy and safety. Here’s an example of the data in a CSV file.
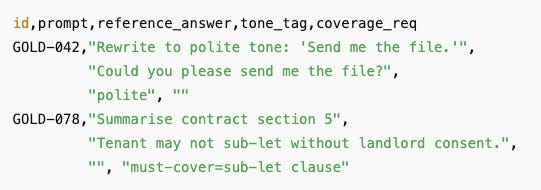
Grade the candidate model/prompt on the golden dataset, either with a simple pass/fail diff or Likert score (of 1-5) - run this against a few hundred prompts. Binary evaluation is preferable. Do this manually to collect both positive and negative examples. Establish a baseline score of the candidate model.
Train a judge model using the golden dataset and the human labels. Continue calibrating (through system prompt refinement or fine-tuning) until the judge model is matching the human expert labels as closely as possible.
Calibrated judge model evaluates future pull requests against the golden dataset, returns a JSON bundle with every metric needed. Humans only review the hardest 5-10% of cases.


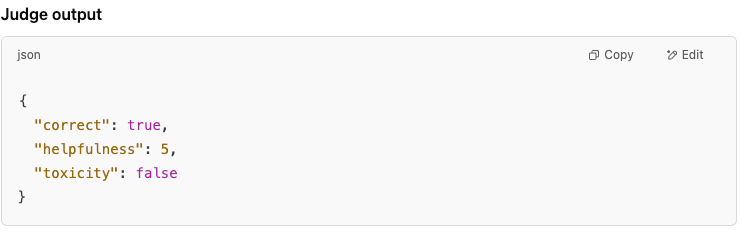
The judge then computes a weighted score for each of the dimensions, e.g. accuracy: 0.91, helpfulness: 4.3, toxicity_rate: 0.4 %. A baseline is established and stored - future pull-requests will have new scores compared to the saved baseline, with rules like:
• accuracy ≥ baseline_accuracy – 0.5 pp
• toxicity_rate ≤ baseline_toxicity
• overall_weighted ≥ baseline_weighted
PRs for changes to models, system prompts, temperature, and RAG tools, need to pass this gate.
This pipeline can be rerun as companies expand into new verticals, forming a repeatable recipe to spin up production-ready AI applications faster than competitors.
That’s the key.
Evals do confer product superiority, but it’s ephemeral.
Speed isn’t just important, it is the moat. The ability to build, ship, learn, and adapt faster than everyone else is the only sustainable edge right now. In a world where everything is open source, everything is demo-able, and everything is one blog post away from being copied, speed is the only thing that compounds.
Execution speed. Hiring speed. Firing speed. Distribution speed. Even decision-making speed. You don’t win because you’re defensible, you win because you’re faster. Killing bad ideas is just as important as the speed of executing against good ones. The opportunity cost of time has never been greater. So if you’re trying to build a moat today, maybe don’t think of it as a castle wall. Think of it as a race. Whoever stacks the most advantages the fastest: products, distribution, talent, infra, wins.
One of the things that I think is is true for any startup is you have to keep proving yourself. Every single insight that we have is a depreciating insight.
You look at a company like Nvidia. If Nvidia doesn't innovate in the next two years, AMD will be on their case. That's why I'm completely okay with a lot of our insights being wrong. If we don't continually have insights that we are executing on, we are just slowly dying.
The judge model decays as new models, user intents and policies change, or as you win enterprises with private samples and an organisation-specific language - you need to construct new golden datasets.
The real moat is the tooling built to run evals, not a single judge model checkpoint or one-off golden dataset.
Infrastructure to continuously run evals includes dataset versioning, a diff UI, CI gate, and a living golden corpus that ingests flagged production data from logs and human expert reviews.
Evals in the wild
Developed a ‘golden’ dataset to test retrieval performance, working closely with human experts
Working closely with experts across clients, developing judge models and measuring metrics like precision (proportion of relevant results), recall (how many relevant documents were found), and NDCG (Normalized Discounted Cumulative Gain)
Labelling is done via A/B preferences and Likert-scale rating from 1-7 on dimensions like accuracy, helpfulness and clarity
Scaling evals through:
Routine evaluations every night to validate day's code changes before production, catching regressions in sourcing accuracy, answer quality, legal precision
Monitor anonymized production data to track performance trends and gain insights without compromising client confidentiality
Evaluate newly released foundation models to identify performance gains and guide integration
Use a large internal benchmark dataset containing clinical audio, gold standard transcripts, human-written reference notes, and rich metadata on patient characteristics.
Over 10,000 hours of medical conversations across internal datasets of patient-clinician encounters, curated ‘challenge datasets’ to pose difficulties and probe weaknesses of clinical ASR models, including clinical conversations laden with new medication names.
Abridge clinicians spot-check notes generated on a curated set of encounters covering a range of clinical scenarios
In their guide on evals:
‘Rigorous evaluation is not a one-time exercise on a static dataset, but a continuous and ever-evolving process that makes large-scale improvement possible.’
‘Evaluation is not just a set of guardrails, but a compass. Continuous evaluation of our product is not just designed to catch or prevent issues, but to drive improvements of our product at scale. As feedback from the field continues to suggest avenues for improving our product, our evaluations expand to cover more aspects of quality beyond the basic requirements of correctness.’
Have more examples to share? Drop me a note at akash@earlybird.com.
Data



Jobs
Companies in my network are actively looking for talent - if any roles sound like a fit for you or your friends, don’t hesitate to reach out to me.
If you’re looking for talent, reach out to have your roles added.
If you’re exploring starting your own company, reach out to me - I’d love to introduce you to some of the excellent talent in my network.
News
SpAItial came out of stealth to build Spatial Foundation Models
Mistral launched an Agents API
Salesforce acquired Informatica to strengthen its Data Cloud proposition
Retool launched their Agents product
Black Forest Labs released new FLUX.1 Kontext image models
Have any feedback? Email me at akash@earlybird.com.