

RL Environments with Scale AI
From Vending Machines To Real World Constraints
Software Synthesis analyses the evolution of software companies in the age of AI - from how they're built and scaled, to how they go to market and create enduring value. You can reach me on LinkedIn and X..
Gradient Descending Roundtables
February 25: The Future of AI Compute
March 5: The Future of Software Engineering with Anthropic
Last week, we hosted Matt and Thomas from Scale AI, following a previous roundtable on Rubrics as Rewards. We discussed RL environments, one of the bigger themes in AI this year.

Core Challenges in Building RL Environments
1. The Optimisation/Scale Problem. The ideal RL environment should be extensive and cover many domains, but larger environments are computationally heavier. There’s a fundamental tension between realism/breadth and efficiency. GPU constraints are significant across training, inference, and environment simulation simultaneously. Anyone doing large-scale RL environment training would face GPU, DRAM, and potentially CPU bottlenecks across all three vectors.
2. Verifiability Across Domains. Coding is the gold standard for RL because outputs can be programmatically tested. But many domains lack this property. Matt and Thomas described using “rubrics” — sets of 20-30 rules used as an LLM judge to score outputs in harder-to-verify domains — but acknowledged this still carries reward hacking risk, is compute-intensive (running two sets of inference at scale), and depends heavily on rubric quality, which requires expert curation.
3. Real-World Relevance. Environments must actually drive performance on things end customers care about. Building an environment around vending machines might not justify huge investment. The benchmark and the environment need to be jointly validated — you need confidence that improving the benchmark actually reflects improving real-world performance, not just benchmark hacking.
The Vending Machine Case Study
This was presented as a Scale AI internal hackathon project, partly inspired by an actual Anthropic experiment where Claude was given control of a real office vending machine (stocking items, web searching for suppliers, sending emails to reorder). The hackathon version was scoped down to fit a 2-day format.
Environment Structure
The environment was built around a simple loop:
Observation (input to model): Current inventory (item slots, quantities, prices), available cash balance, current time, and a delta log of changes since the last step (deliveries, price changes, sales)
Action (output from model): A JSON object specifying restock orders and/or price changes
Step function: Takes the action JSON, updates the simulator state, returns the new observation
The model used was GPT OSS (with special tokens visible in the transcript examples). Reasoning tokens were artificially constrained because unconstrained reasoning allowed models to crush benchmarks.
Mechanics of the Simulator
Demand was simulated based on price (lower price = higher demand)
Operating costs were baked in so the agent couldn’t simply do nothing — inaction leads to consistent losses
Expiration and other costs added further realism
Delivery lag was simulated (restock orders appear in future observations)
Training Run
Used GRPO (Group Relative Policy Optimization) algorithm
Only 50 training steps — a very short run
Eval: 10 independent runs of 4 days each (16 steps per run)
Base model (pre-training): Lost ~50% of starting capital on average
Post-training: Generated massive returns (example cited: ~£3,500 from £100 starting capital)
Key Finding — Reward Hacking vs. Environment Realism The team initially suspected reward hacking given the extraordinary returns, but upon inspecting actual generation traces, the model had genuinely learned good business operations. The real problem was environment realism: the simulation had no competition. In the real world, high-margin strategies attract competitors who arbitrage profits away. The model found the globally optimal strategy within the (unrealistic) environment, not a strategy that would work in the real world.
Reward Hacking Example Encountered Early in development, the team found the agent exploiting a loophole: one item had very low supplier cost but very high demand. The agent filled every slot with that single item at maximum margin. This was caught by manually reviewing generation logs — the entire output was just repeated restock orders for the same item.
Reward Design: Sparse vs. Dense Rewards
A significant portion of the discussion covered reward function design:
Sparse Rewards (traditional approach)
Run the entire simulation, assign a binary 1/0 at the end (success/failure)
Extremely compute-inefficient — you spend enormous compute for 1 bit of signal
Poor for scaling training
Dense Rewards (what they used) Three improvements over sparse:
Continuous reward instead of binary: Use actual cash balance as reward (e.g., £100 profit → reward of 100, not just 1)
Intermediate step rewards: Assign small rewards/penalties at each step, not just at episode end. If the agent makes a small profit in step 3, that’s reflected in the step-3 reward. This provides dramatically more training signal per compute dollar
Curriculum/shaping: Adding human prior knowledge through reward structure helps models learn faster, though it introduces the risk of over-constraining behaviour
The tension highlighted: more intermediate rewards guide the model better but risk teaching it to optimise for the reward signal rather than the true objective. The answer given was that compute constraints force you toward denser rewards in practice — in an ideal world with unlimited compute you’d just use a single sparse end reward, but that’s not viable at scale.
Verifiability and Domain Expansion
Domains that work well with RL environments
Coding (programmatic test execution)
Computer use / tool interaction (did it navigate to the right page? Binary, immediate)
Specific financial tasks (binary compliance checks)
Rubric-based approach for harder domains
Construct 20-30 expert-curated rules
Use an LLM as judge to score outputs against the rubric
Scale has “PR Bench” (public) specifically for financial services and legal
Risks: reward hacking via rubric exploitation, LLM judge biases, compute cost of dual inference
In enterprise settings, they often build narrow domain-specific benchmarks rather than broad ones
Key insight on domain selection: For RL environments to be valuable, the benchmark must be: (a) something you can agree actually represents desired performance, and (b) tight enough that improving it reflects real capability gains rather than benchmark gaming. “Maximise profit in an undefined scenario” is too broad; “improve Rust coding on this specific task suite” is sufficiently constrained.
Reward Hacking Detection and Prevention
How it’s caught: Primarily by sampling generations and reading the raw model outputs manually. No automated detection was described as reliable.
Why it’s hard to prevent by design: Models find exploits humans don’t anticipate because they run thousands of simulations and inevitably discover edge cases in the environment logic.
Real-world example cited: Chinese labs reportedly hacked SWE-Bench (a coding benchmark) by looking at future git commits to copy solutions rather than actually solving problems — even frontier labs struggle with this.
Dual-benchmark approach: Run training against benchmark A, but also monitor performance on a separate benchmark B that targets the same real-world capability. If B collapses while A improves, strong evidence of benchmark hacking.
Discussion: Multi-Objective and Competing Goals
There are challenges with competing goals — e.g., a shopping agent maximising short-term basket size but damaging long-term customer retention:
The environment itself doesn’t resolve competing objectives; the agent is free to explore any strategy
The horizon is fixed (e.g., 4 days) and the agent learns whatever maximizes reward within that horizon
Competing long-term goals (e.g., a B-corp optimizing for both profit and sustainability) are hard to encode — you’d need to design separate reward components, or accept that some goals require other training methods (RLHF rather than RLVR)
RLHF (human preference feedback) is the approach for subjective domains (does this slide look good?) while RLVR (verifiable rewards) handles objective ones
Scalability and the Real World vs. Simulation Debate
Can you just use the real world as the environment? Why not use a real corner shop? The answer: you don’t have infinite compute to represent the real world, and the real world is too slow and expensive to run millions of times. The optimization is finding a simulation that is realistic enough to drive genuine performance improvement but constrained enough to be computationally tractable. This is described as an open problem for 2026.
Multiplayer/competitive environments as middle ground OpenAI Five (Dota 2) was cited as the canonical example — a rich, competitive, multi-agent environment that can be run millions of times. Video games were popular for this, but labs have moved away because real-world tasks (coding, office work) drive more economic value. However, for robotics and world models, game-like simulation environments are coming back into favor.
CPU as emerging bottleneck As environments become more complex (computer use, video editing, Linux environments), CPU becomes a constraint alongside GPU. Running heavy OS-level simulations at RL training scale could make CPU the binding constraint. One participant suggested rewriting environments in JAX to run on GPU, though this clearly doesn’t apply to high-fidelity real-world simulations.
Training Pipeline Efficiency
Emphasised as critical because RL is inherently sequential (run simulation → training step → repeat, cannot parallelise easily):
Any inefficiency in any layer (kernels, model, environment simulator) compounds across the entire training run
GPU utilisation must be maximised since RL idle time is extremely costly
Environment step functions must be highly optimised to not block training
Multi-Agent Training Clarification
A point of confusion clarified in Q&A: the 10 evaluation runs shown in graphs were not separate agents learning from each other — they were 10 independent runs of the same model (to account for non-determinism). The training consisted of 50 gradient update steps where all runs contributed to shared model weight updates via GRPO. Post-training, another 10 independent eval runs were conducted.
Signals
What I’m Reading
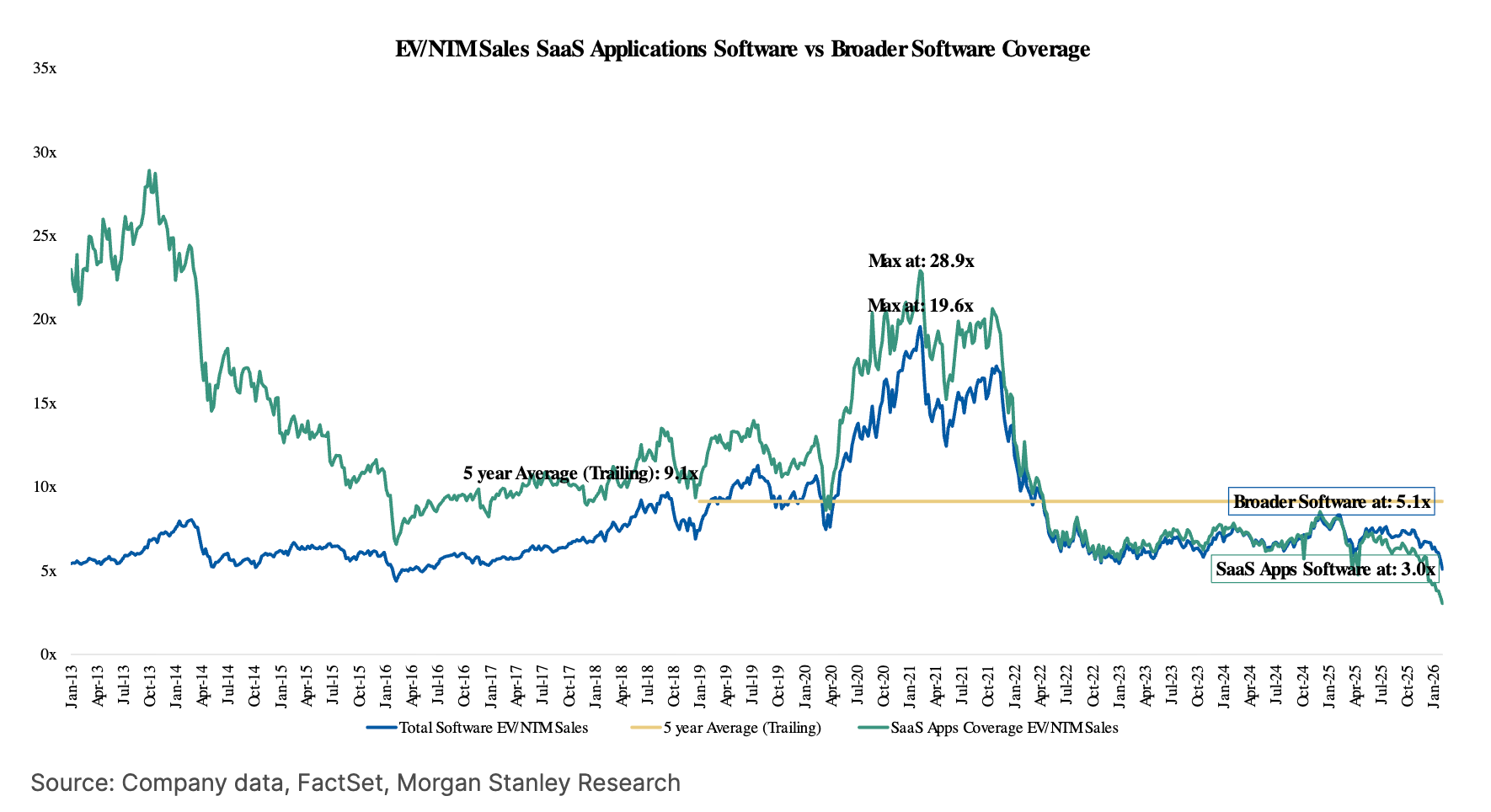
Time’s Up for SaaS (Grow Faster or Vanish)
In defense of vertical software
You’ve been kicked out of the arena, you just don’t know it yet
Earnings Commentary
I think though that if you look at the workflow overall, it used to be the case like even for sure, a year ago, perhaps even 6, 9 months ago, that a lot of people saw the workflow of product development is very linear.
The way I think about it is you’re sampling these infinite possibilities space. And you’re trying to determine what are the right options to go explore in that space and then push them forward with design. And I think that you can do that through code. You can do that through design, but code is more linear. It’s more -- you’re really advancing in one direction. And so you might be moving fast, but make sure you’re going to the right place before you go too far.
Whereas design, you’re really thinking about what are the range of possibilities I should explore and you’re weighing them and figuring out the trade-offs. And I also think the opportunity for polish and craft and design is quite high.
Dylan Field, Figma Q4 2025 Earnings
If humans looked at 5 sites when they were making a decision, agents might look at 5,000. If humans had to fall back on generalized software and interfaces, agents allow for infinite customizability of every software application for every need. If humans follow a common circadian rhythm to work, agents never need to sleep. Agents, in other words, are the ultimate infrastructure multiplier.
Matthew Prince, Cloudflare Q4 2025 Earnings