

Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Codifying Tribal Knowledge Into Vertical-Specific Reasoning

Software Synthesis analyses the evolution of software companies in the age of AI - from how they're built and scaled, to how they go to market and create enduring value. You can reach me at akash@earlybird.com.
Gradient Descending Roundtables in London
November 12th: Small Language Models, Context Engineering and MCP with Microsoft Azure AI
November 18th: Agent Frameworks & Memory with Cloudflare
November 19th: Designing AI-Native Software with SPACING
Last week, Cursor finally released their first frontier coding model, Composer 1 Alpha.
Many are speculating whether the model is a fine-tuned Chinese MoE model, which seems plausible given Cursor’s stance on where their edge lies:
Our primary focus is on RL post-training. We think that is the best way to get the model to be a strong interactive agent.
Earlier that morning, we hosted Aidan and Matt in our office to discuss Scale AI’s recently published research on ‘Rubrics as Rewards’ and its implications for post-training base models.
I’ve written at length about how application-layer companies (or ‘agent labs’) capture reward signals that are becoming increasingly valuable as the cost and complexity of post-training collapse (fine-tuning APIs, managed infra).
‘Reward Engineering’ has proven to be one of the defining AI themes of the year as companies like Thinking Machines Lab, Applied Compute, Osmosis and others emerged with a value proposition of post-training custom models underpinned by high quality reward data. This is all against a backdrop of rapid advances in large model capabilities across objectively verifiable domains like coding and mathematics (where the reward is binary; a proposed code change either runs or it doesn’t).
As soon as this vector of scaling RL became clear, the immediate next question was how to apply it to non-verifiable domains where subjectivity plays a bigger role.
That’s what the Scale paper is focusing on, proposing a richer way of capturing tribal knowledge and reasoning than simple RLHF or preference-ranking. In effect, this is closer to having a process reward model that not only rewards the final outcome but also the steps taken to get to it - and the results are striking.

Below are the notes from our discussion. The relevant papers are here and here - you can also see examples of Rubrics here on the Scale website.

Evolution of Model Training: Post-Training
The progression of post-training approaches:
Supervised Fine-Tuning (SFT) - Early approach
Provides prompt-response pairs with “correct” answers
Useful for smaller, specialised models
Falls away for larger, more generalised models
Can lead to overfitting in complex reasoning scenarios
RLHF (Reinforcement Learning from Human Feedback) - Current approach
Humans select preferred responses between model outputs
Effective for simple queries but struggles with multi-step reasoning
Volume-intensive and requires extensive human evaluation
Risk of reward hacking
Rubrics-Based Approach - New approach
Combines expert knowledge with scalable automation
Particularly valuable for unverifiable domains
The Continuous Evaluation Loop
Training follows a cyclical process:
Evaluation → Data Production → Performance Improvement → Re-evaluation
Typically runs in 6-month cycles with 2-3 iterations per model development phase
Requires constant creation of new data based on previous evaluation results
Includes adversarial components (red teaming) to identify security and safety weaknesses
Understanding Rubrics as Rewards
What Are Rubrics?
Rubrics are structured evaluation frameworks consisting of:
Binary or weighted criteria that can be objectively assessed
Multiple independent factors that together evaluate quality
Specific rules stating what makes an ideal response
Examples to help models understand expectations
Simple Example Structure
For a basic prompt, a rubric might include:
Must address the core question
Should provide specific details
Must avoid certain pitfalls
Should follow appropriate tone/style
Complex Professional Example
In an investment context (e.g., market entry analysis for EVs in South America):
20-30 different evaluation components
Checks for specific data points (market size, timelines, partnerships)
Validates reasoning steps
Assesses structural clarity and relevance
Can be binary (present/not present) or weighted
Three Key Advantages of Rubrics
1. Mitigating Reward Hacking
The Problem: When using simple preference selection, models may learn unintended patterns
Example: Accidentally training preference for “red cars over blue cars” when color wasn’t the intended differentiator
Human evaluators have intrinsic biases that can skew preference data
How Rubrics Help:
Break down evaluation into specific, objective criteria
Exclude components that might drive unintended behavior
Allow larger volumes of diverse data to be generated
A recent Scale AI paper empirically demonstrated reduced reward hacking with rubrics
2. Adaptability
The Challenge: Models need constant refinement based on real-world performance
Errors emerge during deployment
Requirements change based on user feedback
New security issues are discovered
Rubrics Solution:
Much easier to tweak a rubric than retrain thousands of human evaluators
Can quickly adjust weighting or add new criteria
Enables faster iteration cycles
More agile response to identified problems
3. Domain-Specific Control
Different domains require different priorities:
Creative writing: Style, tone, human-like quality matter most
Mathematics: Correct answer and logical reasoning are paramount
Professional contexts: Structural clarity, verifiable data, reasoning transparency
Rubrics enable precise weighting of different evaluation components based on what matters in each specific domain.
The Role of LLMs in Rubric Evaluation
Automation Through AI
Humans design the rubrics (expert knowledge)
LLMs automate the evaluation against those rubrics
This creates scalable volume while maintaining expert-defined standards
Why This Works
LLMs are particularly good at:
Checking if specific elements are present
Verifying binary conditions
Following clear, objective rules
Model Selection for Evaluation
For research purposes (as in the paper): Used GPT-4 Mini as LLM judge to ensure standardisation
For production: Smaller models can work if rubrics are well-designed
Frontier labs building cutting-edge models still prefer human-written rubrics
Smaller budget projects can use LLM-generated rubrics with acceptable results
Practical Applications
Investment Due Diligence
Multi-step reasoning example:
Initial analysis of market conditions
Financial projections
Partnership identification
Risk assessment
Each step can have its own rubric
Important to maintain observable reasoning pathways
Healthcare/Medicine
Unverifiable domain characteristics:
No single “correct” diagnosis for complex presentations
Expert intuition difficult to codify
Rubrics help capture decision-making criteria
Can evaluate diagnostic reasoning steps
Legal Services
Contract analysis requirements:
Specific clause identification
Risk assessment
Compliance checking
Precedent application
Insurance
Knowledge extraction challenge:
Much expertise exists only “in people’s heads”
Retiring workforce creates knowledge drain
Rubrics help codify expert decision-making
Quality assurance already uses similar scoring systems
Technical Details from the Research
Experimental Setup
Base model: Qwen 2
Comparison: Rubrics approach vs. direct preference ranking
Evaluation: GPT-4 Mini as judge for standardisation
Training: Offline RL (not online due to cost)
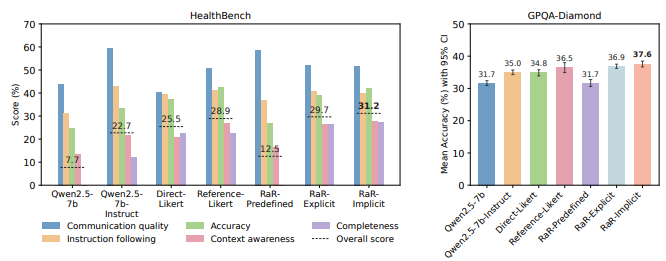
Performance Results
The rubrics approach showed improvements in:
Context awareness
Communication quality
Accuracy in reasoning-heavy tasks
Key Finding
Rubrics are particularly effective for:
Complex, multi-step reasoning
Domains without clear “correct” answers
Professional/expert knowledge domains
Tasks requiring observable reasoning chains
Critical Considerations and Debates
Evaluating the Evaluators
The recursion problem:
How do you evaluate whether rubrics are good?
Ultimately requires testing impact on model performance
Need comprehensive evaluation datasets for each domain
Iterative refinement based on real-world results
Human vs. Automated Rubric Creation
For frontier performance: Human-written rubrics still superior
For smaller models/budgets: LLM-generated rubrics can work
Key insight: The intersection of domain expertise and understanding of model behaviour is rare and valuable
Market Implications
The Changing Nature of AI Data Work
From volume to expertise:
Less emphasis on mass preference labelling
More focus on expert rubric design
Smaller teams of highly skilled data creators
Higher per-person cost but better outcomes
Professional Knowledge Extraction
The hidden expertise problem:
Most professional knowledge isn’t documented
Exists in practitioners’ intuition and experience
Examples: Insurance brokers, doctors, lawyers, investment analysts
Rubrics provide a framework to codify this tacit knowledge
Future Opportunities
Industries with retiring workforces (insurance, legal)
Domains with complex, multi-step reasoning
Applications requiring explainable AI decisions
Situations where “average” data isn’t sufficient
Autonomous Improvement Discussion
The Holy Grail Question
Can frontier models achieve fully autonomous self-improvement using only AI-generated rubrics?
Current state:
Deepseek recently claimed full self-improvement in specific domains
Depends heavily on model size and domain complexity
Still an open research question
Likely varies significantly by application
Hybrid Approaches
Most realistic near-term:
Human-designed rubrics for frontier domains
LLM-automated evaluation and data generation
Human oversight for refinement and validation
Iterative improvement cycles
Key Takeaways
Rubrics represent a middle ground between fully manual RLHF and purely automated approaches
Most effective for unverifiable domains where there’s no single correct answer but expert judgment exists
Enables scaling expert knowledge by codifying it into structured, scalable evaluation criteria
Reduces but doesn’t eliminate human involvement - shifts humans to higher-level rubric design rather than individual preference selection
Particularly valuable for professional applications in law, medicine, finance, and other expert domains
The data market is shifting from volume-based preference ranking to expert-driven, rubric-based approaches
Quality of rubric design is critical - requires intersection of domain expertise and understanding of AI model behavior
Future Directions
Application to visual language models and robotics
Integration with existing quality assurance frameworks
Automated rubric generation for non-frontier applications
Expansion into multimodal domains
Development of standardised rubric libraries for common domains
Signals


What I’m Reading
Top Down and Bottom Up Investors
The Case for the Return of Fine-Tuning
Is Diffusion the Future of LLMs?
Marc Andreessen and Charlie Songhurst on the past, present, and future of Silicon Valley
Europe’s Hidden Sovereign AI Gem: Nebius
Earnings Commentary
“Today, virtually every business is becoming a software business, and AI has made software easier than ever to create. In this world, we believe your design, your craft and your brand’s point of view is what’s going to make your product and your company stand out. Design is now the differentiator. It’s how companies win or lose.“‘
Dylan Field, Figma Q2 Earnings Call
When people hear [Data Cloud], naturally assume, this must be a Snowflake competitor or a Databricks competitor, and that’s just not the case. Snowflake and Databricks and BigQuery and Redshift are among our biggest partners.
Salespeople do not log in to Snowflake. Snowflake is fantastic, but it’s really analysts that tend to log into Snowflake, not salespeople. People in the contact center do not log into Databricks... That’s the problem that Data 360 really, really, really solves.
Stephen Fisher, Salesforce Analyst Day
Our most recent Adobe Digital Index data which is based on online transactions across over 1 trillion visits to U.S. retail sites, shows that LLM traffic grew 4,700% year-over-year in July 2025. The rapid changes in consumer behavior and expectations in the era of AI are forcing brands to reinvent marketing and customer experience.
Anil Chakravarthy, Adobe Q3 Earnings Call
We estimate 80% of the leading AI companies already rely on us. A huge percentage of the Internet sits behind us. The agents of the future will inherently have to pass through our network and abide by its rules. And as they do, we will help set the protocols, guardrails and business rules for the Agentic Internet of the future.
Matthew Prince, Cloudflare Q3 Earnings Call
Machines simply can’t govern themselves, AI is like any other enterprise asset, it needs to be cataloged, tracked, supervised and secured. ServiceNow’s configuration management leadership gives us and our customers a clean single pane of glass to govern all artificial intelligence.
Bill McDermott, ServiceNow Q3 Earnings Call
Have any feedback? Email me at akash@earlybird.com.
great explanation!