

Application Software Is Dead, Again
Data Fabrics, Agent Labs, Moving Up And Down The Stack

Software Synthesis analyses the evolution of software companies in the age of AI - from how they're built and scaled, to how they go to market and create enduring value. You can reach me at akash@earlybird.com.
Gradient Descending Roundtables in London
November 18th: Agent Frameworks & Memory with Cloudflare
November 19th: Designing AI-Native Software with SPACING
November 26th: Open Source AI with Alibaba Qwen
December 4th: The Paper Club: AI Wrapped 2025
Reinforcement Learning and Multimodal Models with Zoe (Dawn Capital) and Doubleword.ai
Application Software Is Dead, Again
Three years in, the debate of value accrual in AI has only intensified as the model labs have transformed into product companies capable of shipping excellent consumer and developer-facing products at a clip that’s incomparable to incumbents of the past.
The debate was reignited on X this week.

There was a thoughtful follow-up from the author, which roughly approximates to: past technology cycles afforded more time for startups to create and capture value, whereas in AI the model layer is changing every 9-12 months, creating an impossibly short timeline for startups to outrun obsolescence by building enterprise relationships and an enduring brand.
The discourse on application software is of course one part of a broader discussion on how software is fundamentally changing, and, importantly, over what time horizon.
Agents Built On The Lakehouse
One view of the future, which I’ve written about before, is that we’re marching towards enterprises preparing their data estates for economies of agents to perform work end-to-end.
The unbundling and bundling of the modern stack is instructive.

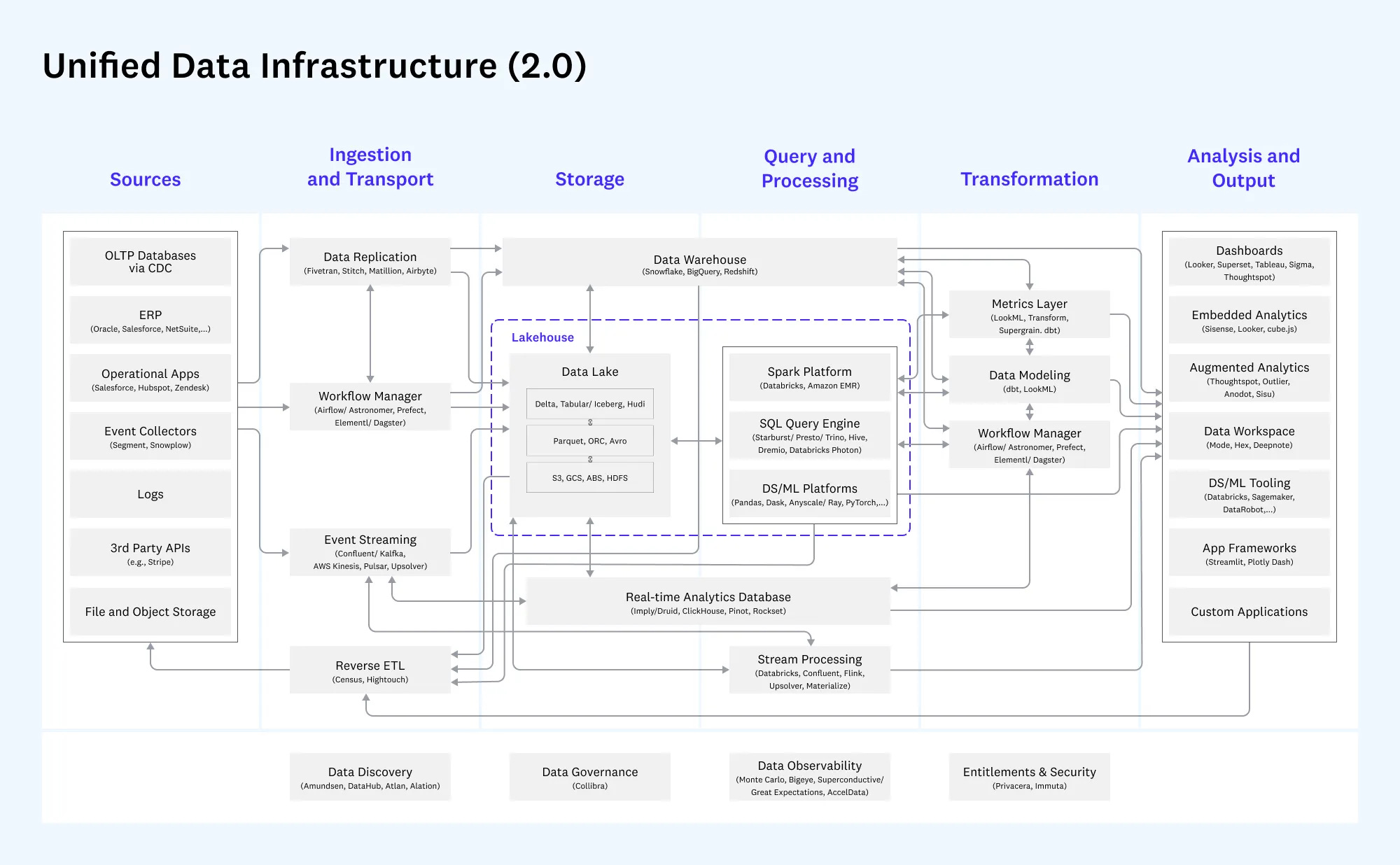
As Ethan Ding wrote on the fivetran and dbt merger:
every $1 to dbt means $10 to snowflake. i’ve heard numerous snowflake account execs confirm that while dbt only recently crossed $100m in revenue, they’re driving $500m in snowflake costs. which makes snowflake reps love to sell dbt in all of their transactions. this caused the dbt community to grow massively. which means snowflake account execs were basically dbt’s commission-only sales team. except instead of splitting the money, dbt got 2% and snowflake kept 98%. very generous partnership structure.
The majority of the dollars spent on data and value always accrued to Databricks/Snowflake, where the computing/querying was happening. For a while, they were happy to support an ecosystem of adjacent tooling so long as they were driving consumption upstream/downstream.
Eventually, the Lakehouses decided to consolidate the sprawling landscape of data infrastructure vendors on the premise of a lower TCO for their customers (fewer FTEs needed to manage different vendors).
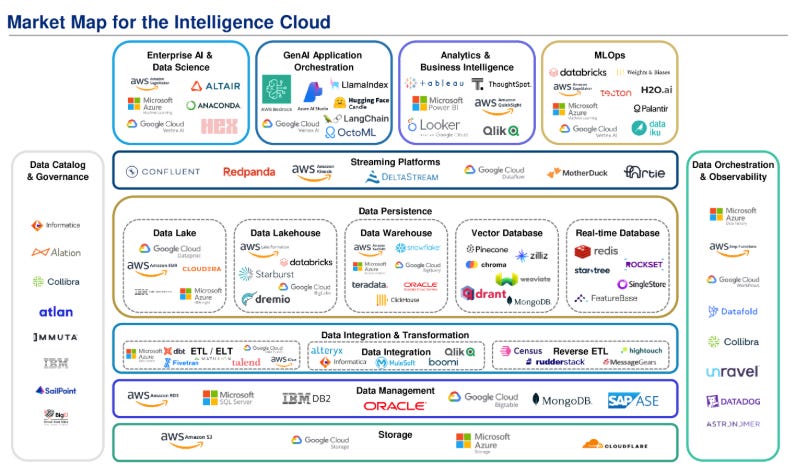
This view of the world would see enterprises continue to embrace open table formats, consolidate their data and store it cheaply, and, most importantly, decide what query engine to use.
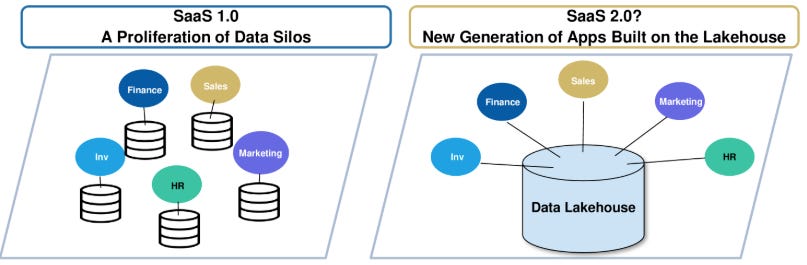
The same reasoning explains why Salesforce acquired Informatica, ServiceNow is focusing on their Data Fabric, and SAP announced a partnership with Databricks: help customers consolidate their data and perform work in your environment.
The only difference is that instead of humans performing the queries, eventually it’ll be agents.
Tooling for observability, governance, analytics, and security will still be necessary for enterprises to comfortably deploy agents fairly autonomously across their data estate.
For this view of the world to prevail, the customer’s business logic or domain-specific reasoning will have been codified (whether that’s packaged by a vertical AI vendor focused on domain-specific reasoning, captured by a Palantir FDE sitting with your subject matter experts, or learned through processing of your data corpora).
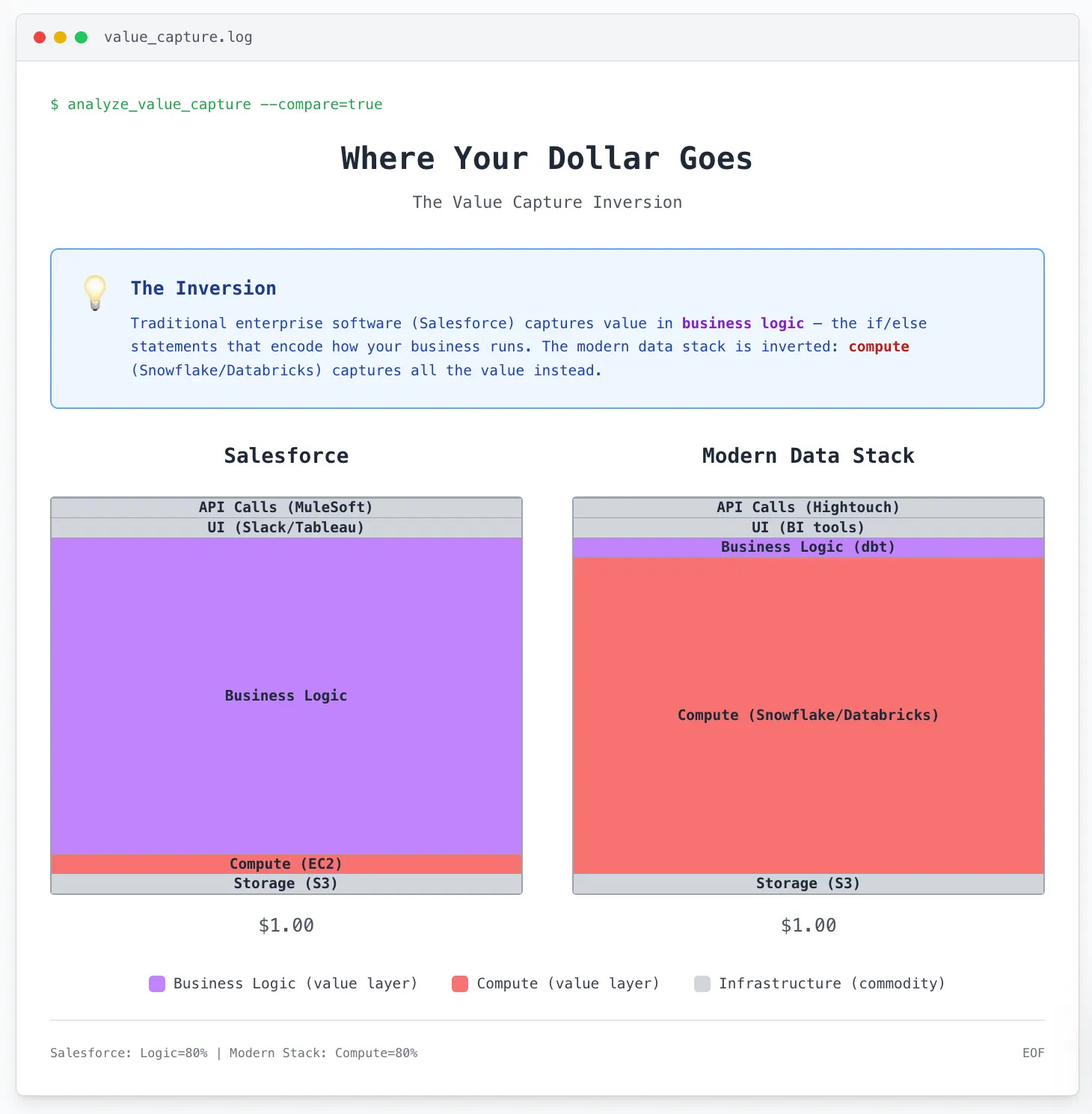
That’s of course across hundreds or thousands of processes, which is why the concept of an equally large number of small language models tuned to each specific process (running locally at little to no inference cost/COGS) makes so much sense.
AI’s Diffusion Rate
As plausible as it sounds, this scenario is still many, many years away, for two key reasons.
First, despite the unprecedented diffusion rate of AI for such a consequential technology, the change management required for enterprises to transform how they operate in a post-AI world is greater than anything that’s come before.
Satya Nadella opined on the future of software in an interview by Dwarkesh Patel and Dylan Patel:
Our business, which today is an end user tools business, will become essentially an infrastructure business in support of agents doing work.
However,
What took 70 years, maybe 100, 150 years for the industrial revolution may happen in 20 years, 25 years. I would love to compress what happened in 200 years of the industrial revolution into a 20-year period if you’re lucky.
Even if the tech is diffusing fast this time around, for true economic growth to appear, it has to sort of diffuse to a point where the work, the work artifact and the workflow has to change. And so that’s kind of one place where I think the change management required for a corporation to truly change, I think is something we shouldn’t discount.
The second key constraint is the development of agents, which we should measure over a time horizon of decades rather than years, as Andrej Karpathy has argued:
When you’re talking about an agent, or what the labs have in mind and what maybe I have in mind as well, you should think of it almost like an employee or like an intern that you would hire to work with you. For example, you work with some employees here. When would you prefer to have an agent like Claude or Codex do that work? Currently, of course, they can’t. What would it take for them to be able to do that? Why don’t you do it today?
The reason you don’t do it today is because they just don’t work. They don’t have enough intelligence, they’re not multimodal enough, they can’t do computer use and all this kind of stuff. And they don’t do a lot of the things that you’ve alluded to earlier. You know, they don’t have continued learning. You can’t just tell them something and they’ll remember it. And they’re just cognitively lacking and it’s just not working. And I just think that it will take about a decade to work through all of those issues.
This is by no means understating the diffusion rate of AI among consumers, where we’re still in the early innings of building AI-native experiences, let alone on new computing interfaces like wearables.
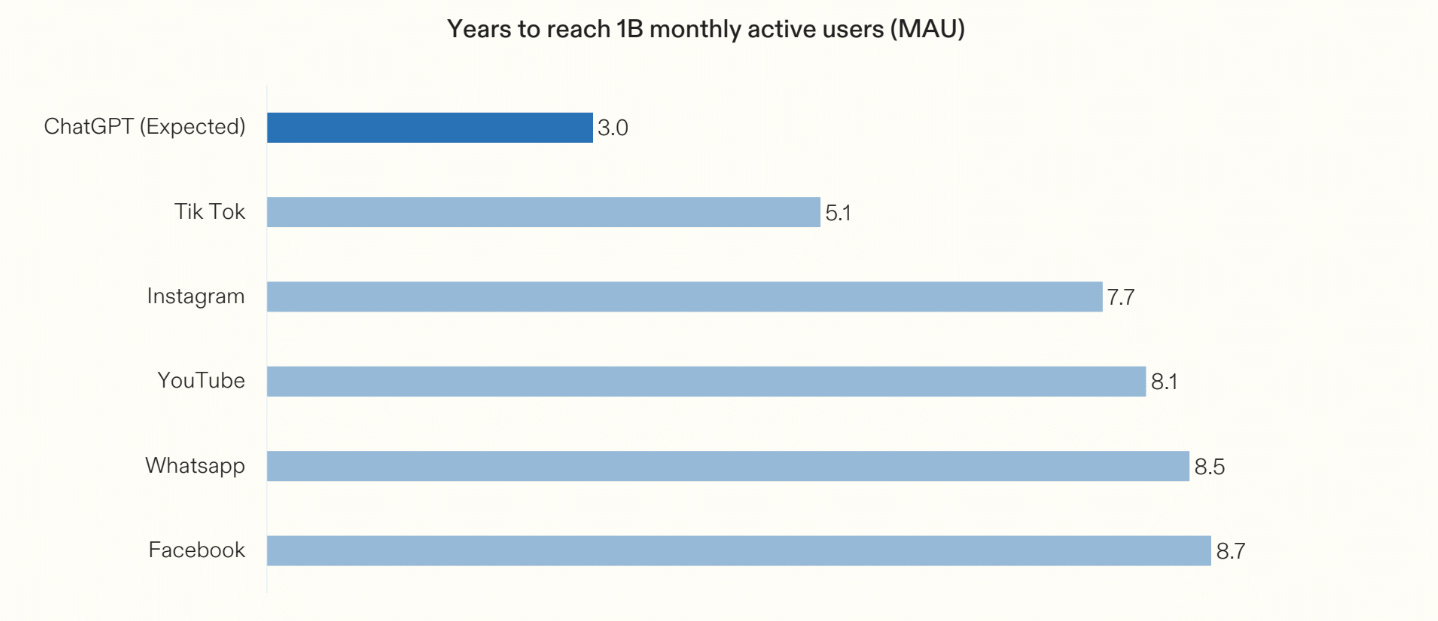
Computer using agents will no doubt soon be reliable at common consumer use cases like travel and shopping, with the enabling infrastructure for agentic commerce quickly coming together, further accelerating adoption. The consumerisation of enterprise software will continue to be a tailwind for AI penetration, and AI will catalyse adoption among SMBs in verticals that have been resistant to software eating the world.
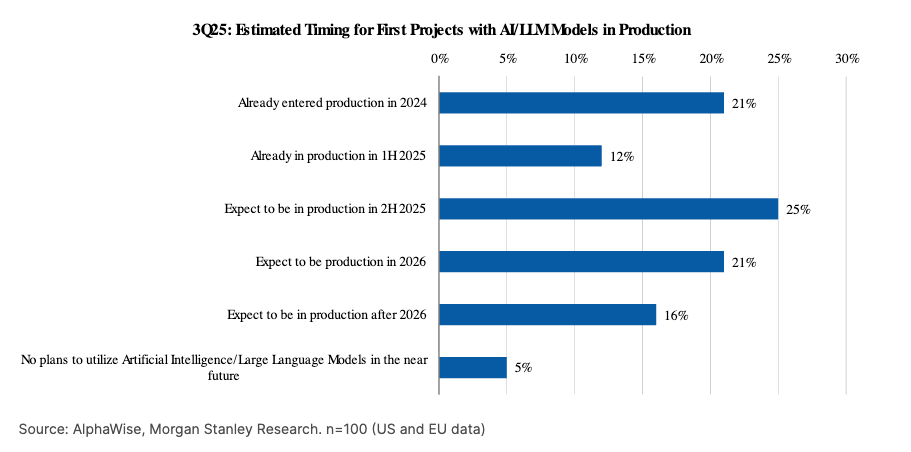
The ground truth in the enterprise is that over half of enterprises have yet to put their first AI projects into production.
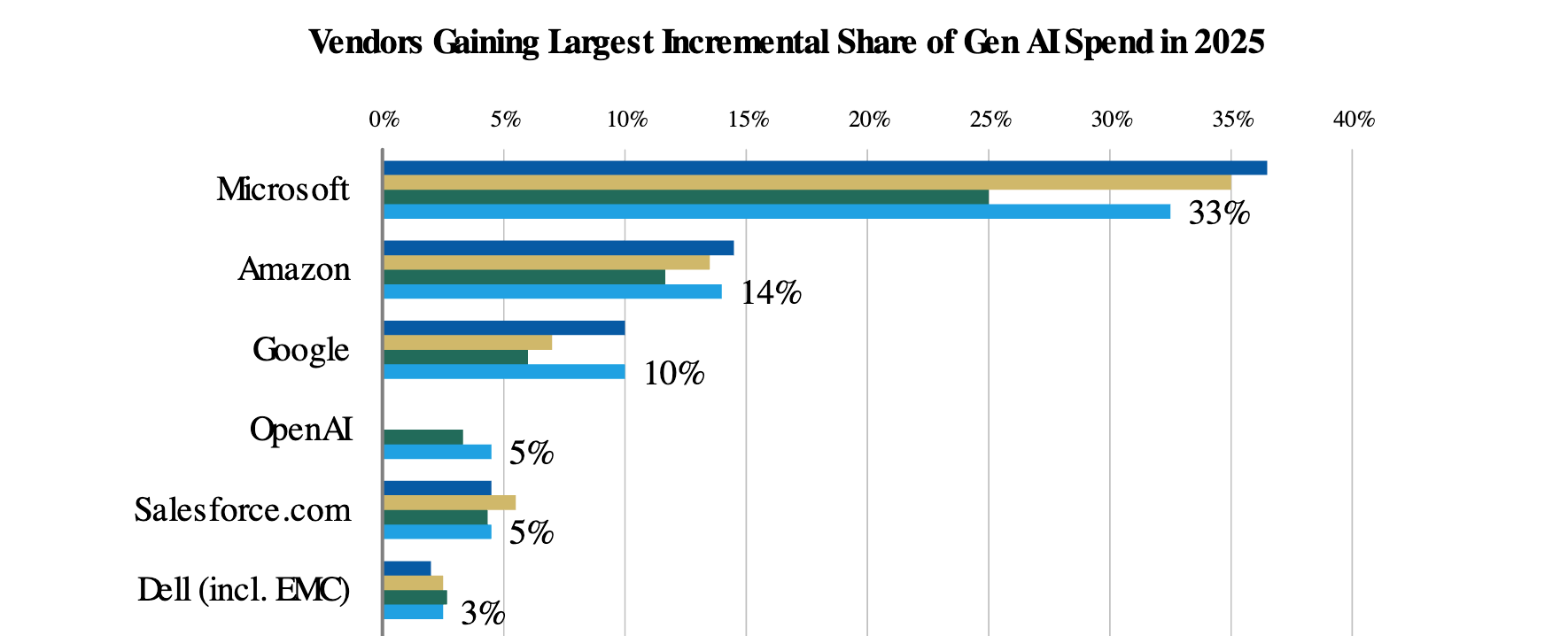
With Microsoft expected to be the biggest share gainer/beneficiary of AI workloads.
There are a lot of reasons behind this, but the structural reasons of change management and model capabilities are the two biggest ones.
It goes without saying that there are already use cases where the capabilities meet the minimum viable quality threshold and outsourcing was the default, such as customer support, where large companies are already being built.
The breakout companies in those verticals, though, are not cleanly defined as application or infrastructure companies - they’re both.
Agent Labs
I’ve written before about how applied AI companies closest to the end user earn the right to collect valuable training/reward data that can then be used to tackle gnarly infrastructure/research problems that help AI products cover the last mile in the enterprise, which has always been the longest.

The customer support market is an early indicator of this, where research engineers/scientists are becoming a more common hire in order to train custom models (e.g. reranker models) that drive higher resolution rates, one of the key metrics AI startups are being benchmarked on.
I’d predict that the title ‘Member of Technical Staff’ will become much more common at companies that have historically been deemed ‘application software’ companies.
This view of the world will see the lines between layers of the AI stack continuously blurring, perhaps even earlier than they already are in the current cohort of AI companies. Model labs will continue moving up the stack, whilst agent labs will relentlessly move down the stack to capture more margins.
An analysis I’ve been wanting to do for a while is to look at the attach-rate for model lab products to get a better sense of whether the right-to-win that is typically ascribed to the labs is justified. Of course, IBM, Microsoft, and Google were monoliths in different technology paradigms that had ambitions to win in as many markets as possible.
The notion that this time is different is appealing.
Reasoning from first principles, models continue to advance as a function of the data we can provide them, with the focus shifting to reasoning data. The labs will inevitably go after select verticals where marketplaces like Mercor make the acquisition of expert reasoning data easier than ever.
In vertical software, however, the heterogeneity in workflows/reasoning steps/data sets/integrations/GTM channels would make it very difficult for the model labs to execute against each opportunity with the level of focus that a dedicated agent lab can channel.
In horizontal software, being multi-model is a strength when measuring a portfolio of models against different criteria for specific use cases.
As agents become capable at handling existing workflows end-to-end, the best companies of the future will leverage AI to define new ways of creating value that we can only imagine.
We won’t have to wait long for that future, as the revenue ramp of Cursor, Sierra, Cognition, and various other companies is already proving. After all, some of the biggest companies in recent memory have built large businesses selling to other tech companies.
These customers embrace the future and build their technology stacks from the ground up for performance.


Time will tell which version of the future this cohort of AI companies builds on.
Signals
What I’m Reading
RL Environments and the Hierarchy of Agentic Capabilities
Earned Intuition #003: Vertical AI: What Would You Never Ask a Human to Do?
2025 Vertical & SMB SaaS Benchmark Report
Earnings Commentary
As busy as we are with these mega deals, our main focus is still to build our own core AI cloud business. We made great progress here with AI native start-ups like Cursor, Black Forest Labs and others. The economics and the cash flow of mega deals are attractive in their own right, but they also enable us to build our core AI cloud business faster. This is our real future opportunity.
Arkady Volozh, Nebius Q3 Earnings Call
The data products, the semantics, the business context, the orchestration of the agents in a business context is all with SAP... Everything what happens on AI agents in the context of the SAP applications, in the context of the business processes, in the context of enterprise analytics that is SAP.
Christian Klein, SAP Q3 Earnings Call
You used to have to take a company private to change the unit economics of it. What we’re doing in enterprise is providing a private equity like transformation in the public markets, in the public space under the current leadership.
Alex Karp, Palantir Q3 Earnings Call
Have any feedback? Email me at akash@earlybird.com.
This article comes at the perfect time! How does AI's rapid pace afect value accruel? Very insightful.