

AI's Optimisation Era
Owning Intelligence, Hill-Climbing Machines and Private Evals
Owning rather than renting intelligence has never been more important. This was true even before export controls on frontier models kicked in.
Frontier tokens cost 10x as much as the best open models.
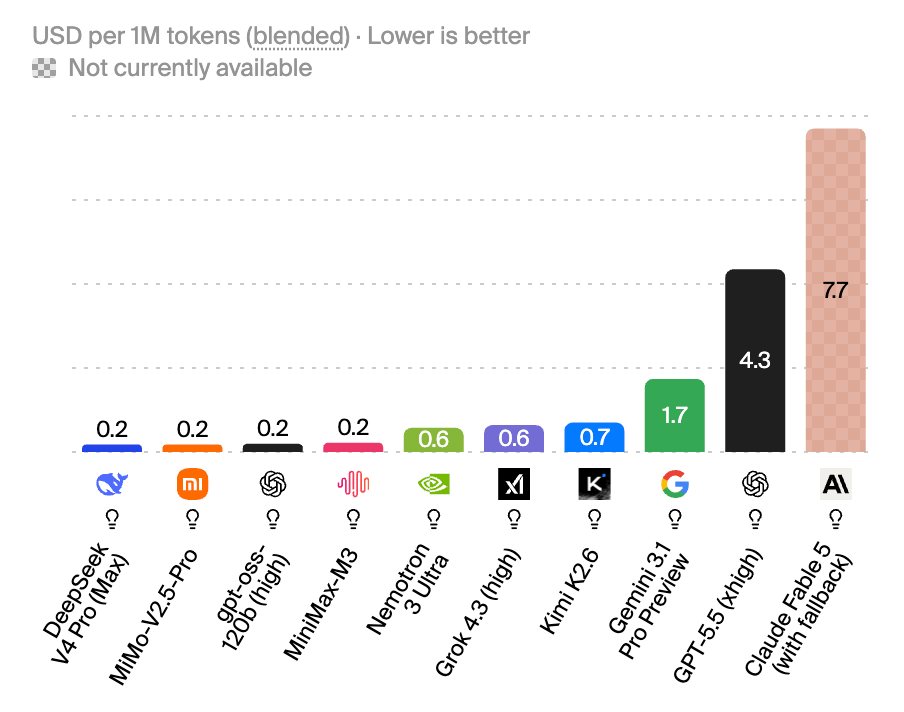
It’s a similarly stark picture when assessing cost per task.
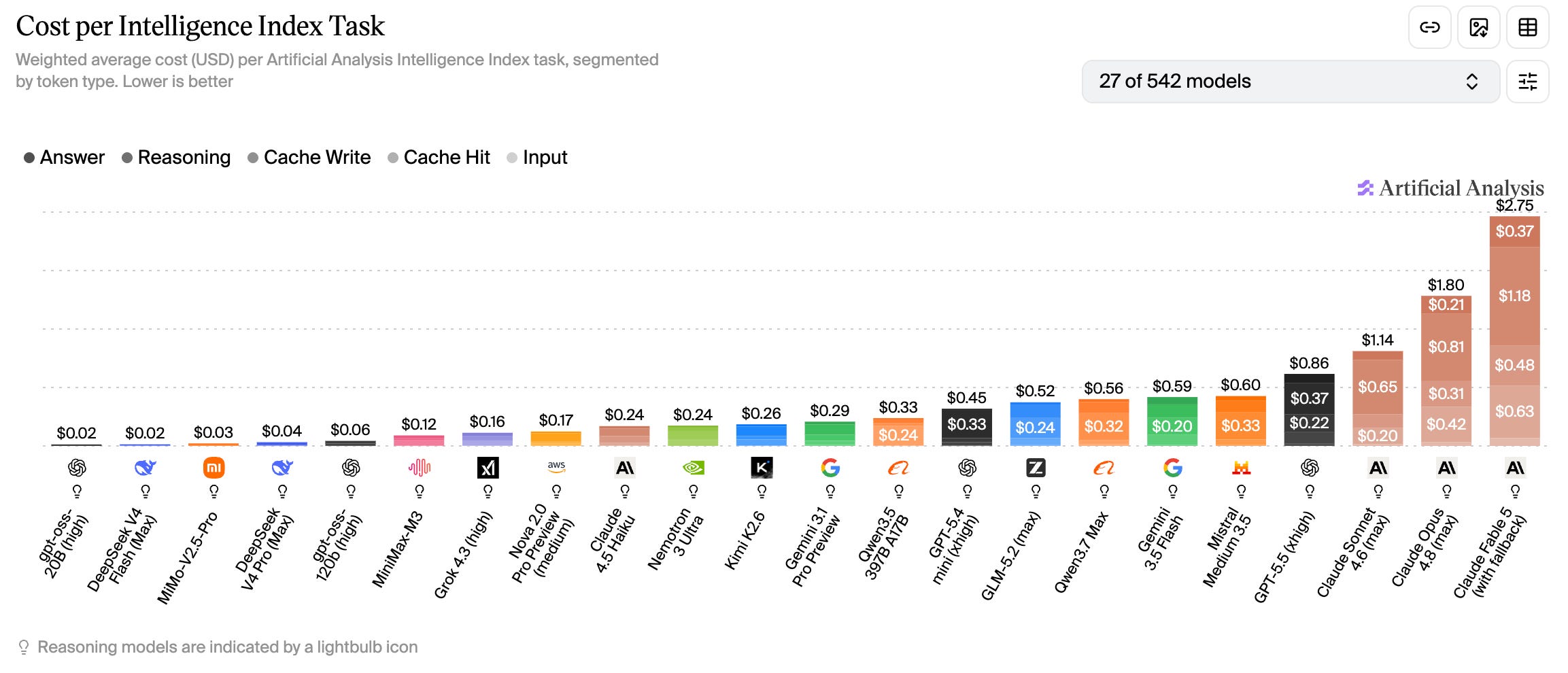
The reality is that the majority of enterprise software workflows don’t need frontier intelligence.
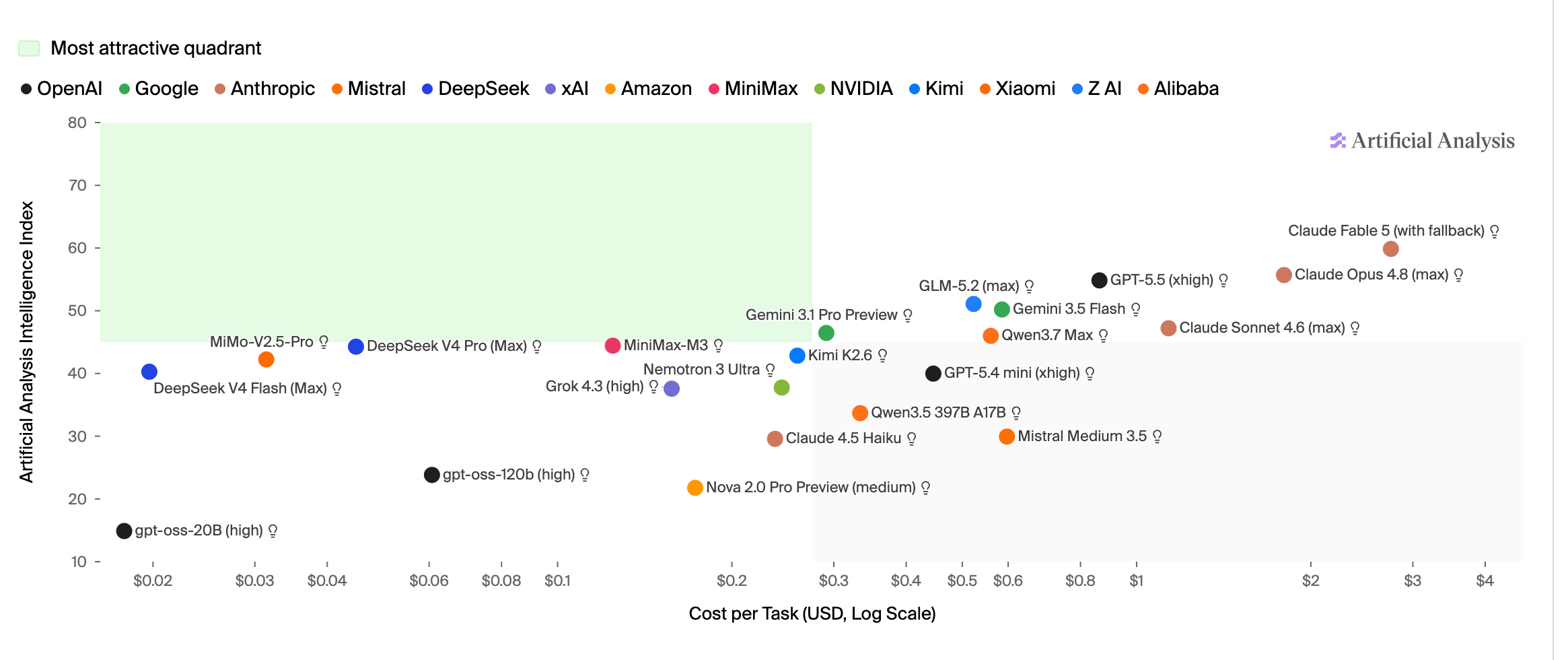
The case for owning intelligence rather than renting it isn’t just an economic one, but also one based on performance.
It’s clear to me, then, that intelligence here is a runtime phenomenon. Two deployments of byte-identical weights can give you two wholly different experiences: the precision and quantization they’re served at, how the cache gets managed, the pool your request lands in, the speculative decoder racing ahead, the reasoning effort, the noisy neighbors of multitenancy.
If you don’t own the serving engine, the precision, whether the KV cache is paged or quantized, how requests get batched and scheduled then every one of those choices is a vendor’s right to change without telling you. If you do, then when the output changes you have recourse: you can git blame or bisect instead of flaming your vendor on r/{{whatever}}.
Adam Azzam of Modal compares model weights to a master tape: pristine, mixed once, sitting in a vault. But you never hear the master tape directly; you hear it played back through a mixing board and room someone else controls: the labs.
That playback chain is the serving infrastructure: routing, quantisation/precision, caching, batching, reasoning effort. It’s why your product has regressed on your evals even though the model was the same.
In addition to serving infrastructure, Lin Qiao of Fireworks makes the case that the frontier is more than just the best closed models from Anthropic and OpenAI:
There isn’t one frontier. There are many.
A frontier model is one kind of frontier.
A model post-trained on years of proprietary company knowledge is another.
A specialized model that solves one narrow problem better than anything else is another.
A router mapping request to a collection of models working together to outperform any individual model on many tasks.
Several applied AI companies have stepped up efforts to own their intelligence. The most notable example is Harvey, who have published multiple papers on how they’re post-training models for their domain, prompting cofounder Gabe Pereyra to explain the various research angels they’re exploring:

In post-training Nvidia’s Nemotron family, they’ve pushed out the Pareto frontier.
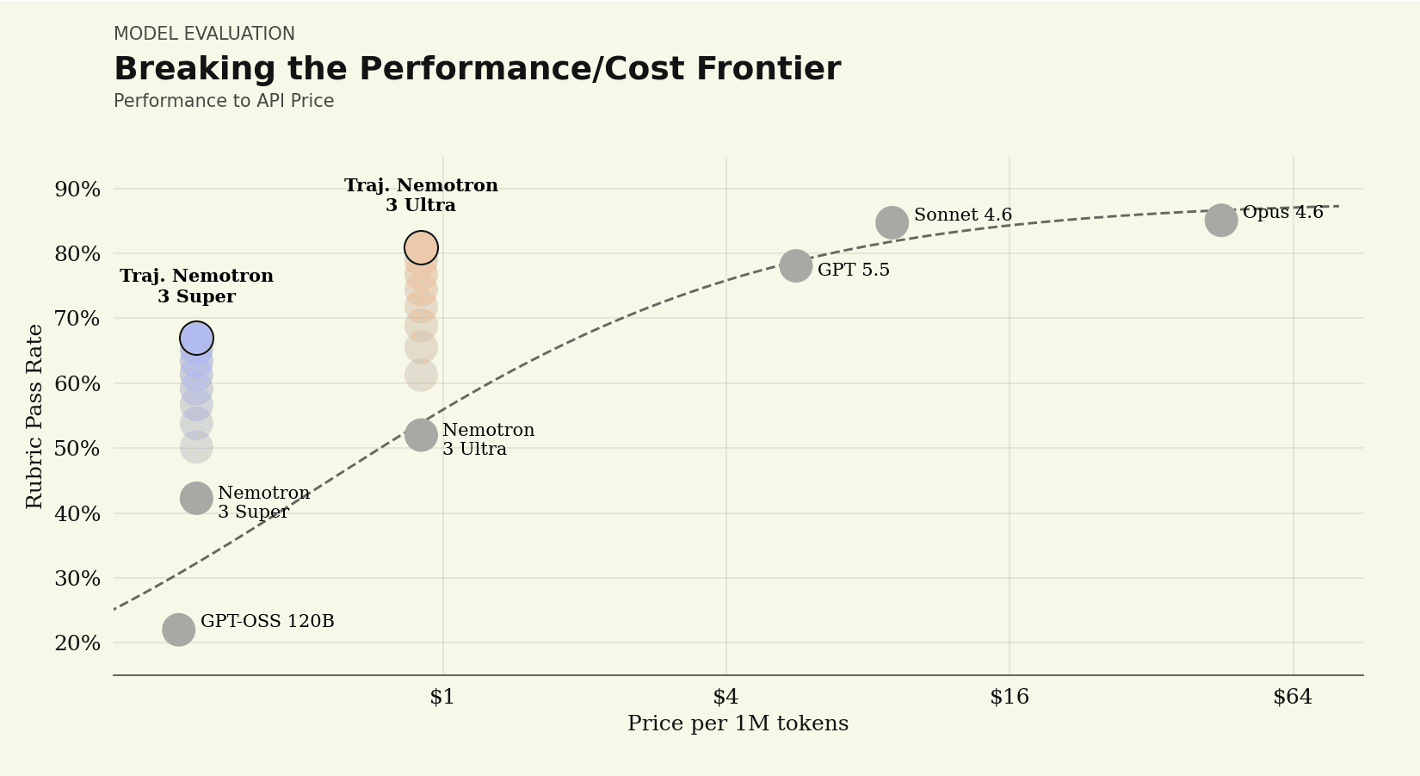
Harvey’s Legal Agent Benchmark, Cursor’s CursorBench, Rogo’s Big Finance Bench, and Cognition’s Frontier Code are examples of what Sarah Guo characterised as the untrainable corner of enterprise work.
The prize is the last corner, the untrainable one: frontier work whose correctness exists only in private. You can see it in the inference clouds hosting the AI-native pioneers, where the vast majority of tokens are generated by custom models, not generic open ones.
The evaluation that decides real money is private and per-firm: what this firm, on this kind of matter, will accept as good work, and it is nowhere near finished, because the depth of the law dwarfs any public test. OpenEvidence is settling what a safe clinical answer looks like. None of this is really measurement, it is judgment about what is true and what is good, written down until it becomes the standard everyone else is measured against, and a foundation lab can’t author it however smart it gets, because that standing only exists inside the field.

If applied AI companies can hill-climb on domain-specific evals, Satya Nadella and Microsoft AI are betting that enterprises can too:
Companies need to turn their workflows, domain knowledge, and accumulated judgment into AI systems that improve with each use. Private evals should capture whether a model is actually improving against outcomes that matter to the business (not just external benchmarks!). Private reinforcement learning environments should let models grow stronger on real traces from inside the organization. Its knowledge base makes institutional memory queryable and use of tokens more efficient.
The technical report on MAI-Thinking-1 breaks down the components needed for enterprises to build their own hill-climbing machines:
The integrated process of building data pipelines, training infrastructure, reinforcement learning environments and rewards, evaluation suites, and safety tests that turn model development into an empirical optimization loop on a specified domain.
Optimisation doesn’t stop there.
Owning intelligence has clear cost and performance benefits, but there’s more systems engineering to be done.
The empirical optimisation loop Microsoft are advocating for isn’t just to hill-climb on on performance, but across several dimensions.

It’s becoming clearer that energy is the ultimate bottleneck in AI inference. Workload-Harness Fit is narrow form of optimisation and needs to be extended all the way to measuring intelligence per watt.
In pursuing that optimisation, the kind of compound systems engineering that’s needed becomes clearer.

Satya Nadella: Take that example we showed with Land O’Lakes today, which is, here’s an agent, and there is an outcome you care about, I was able to use a model that is using 500B, I was able to use a 5B, and have it really deliver the same outcome, why would I not use that?
Ben Thompson: That does seem to be a very different thing about this period. It seems clear that’s going to be a huge thing in enterprise going forward, using the right model, optimizing, it’s like we didn’t get to the optimization stage of the PC era.
OpenRouter’s compound Fusion model is the best example of this to date.
A combination of Gemini 3 Flash, Kimi K2.6 and DeepSeek V4 Pro costs c. 20% of the Fable 5 + GPT-5.5 combination whilst only being 4% worse on a deep research benchmark.


For all of these reasons, I see scenarios 1 and 3 have the strongest tailwinds, with significant second-order effects on frontier lab economics, cloud inference and margins across the stack.
