

2026 Predictions
Mid-Training, Advertising, Industrial Policy...

Software Synthesis analyses the evolution of software companies in the age of AI - from how they're built and scaled, to how they go to market and create enduring value. You can reach me at akash@earlybird.com.
Hey everyone,
Hope you had a good break over the holiday period!
I took time off from writing to recharge. Time away from the constant stream of AI news was a priceless way to mentally reset, step back, and think about the ‘bigger picture’, as they say.
Step back to 2015, when OpenAI was just founded. Today, much of the global economy’s growth depends on AI and its attendant infrastructure buildout. There are no benchmarks that can’t be beat.
What progress will the next 10 years hold? It’s perhaps terrifying and captivating in equal measure.
I have two primary vehicles for thinking about the future: writing and community. I’m excited to resume both writing and the community building that we started last year with the ‘Gradient Descending’ series of events.
As always, I’m grateful to each and every reader for joining.
1. Mid-Training: Enterprises Shop Model Checkpoints
Model training will become more of a continuum.
Enterprise customers will increasingly be able to choose their preferred model checkpoints to inject their internal data.
As Ben Thompson wrote of AWS’ Nova Forge offering:
Right now you have two ways to incorporate your company’s data into an AI model: first, you can use RAG to basically have a model search your company’s data in the context of providing an answer. Second, you can post-train a model on your company’s data. The shortcoming in both approaches is that your company’s data isn’t actually in the model, which can lead to unsatisfying results.
Nova Forge is an offering built on AWS’s internally produced AI models; because they own the Nova models, they own the training checkpoints. What you can do with Nova Forge is choose a checkpoint — say, when the model is 80% trained — and infuse your company’s data at that point, so that the data is integrated into the model itself, and not simply searched or trained-in after-the-fact.
As more practitioners seek the bare ‘cognitive core’ capabilities of language models without the drawbacks induced by low-quality internet data, it’ll be interesting to see how this market evolves to cater to this demand.
Will customers choose models at the 80% training stage, or will they desire even earlier checkpoints for the above reason? It depends on how much transparency will be provided into the training corpus. Then again, that level of disclosure hasn’t been met by most of the ‘open source’ model providers who’ve chosen to only go as far as making their weights open.
2. Advertising Finally Arrives
OpenEvidence, rumoured to be raising at a $12bn valuation, grew from $8m ARR in 2024 to c. $150m (!) as of the end of November 2025.
This astonishing growth was purely advertising revenue. This model enabled viral adoption by clinicians, as the platform now serves 15 million clinicians per month (40% of the US market). Not bad for a four-year-old company.
OpenAI’s recent Gemini-induced Code Red mode delayed their roll-out of advertising, but as Ben Thompson has argued many times, advertising is the inevitable internet business model.
xAI’s position in the ‘Muskonomy’ (SpaceX/Starlink, Tesla, X) may yet see it become more competitive in the consumer market, but for now I see it as a two-horse race between Google and OpenAI. Both are still aggressively competing for market share, to be sure, but engagement metrics will continue improving as agentic commerce takes off (and more capabilities like memory are unlocked/improved).
Advertisers will finally be able to occupy the valuable ChatGPT/Gemini real estate.
3. European Industrial Policy Gains Momentum
Kanishka Narayan’s (UK Minister for AI and Online Safety) vibeshift narrative is much needed.
It’s easy to be cynical about Europe’s prospects, but I’m taking a glass half-full view and believe that policymakers are going to invest heavily across the AI supply chain.
From faster planning permissions, to new sources of energy and to data centre construction in AI Growth Zones, the physical, atom-based constraints on AI need to be lifted in order to realise accelerated GDP growth.
The EU’s AI Continent Action Plan has a number of promising proposals, including the The Cloud and AI Development Act which aims to triple the EU’s data centre capacity within the next five to seven years. The Plan also weighs up the importance of data foundries, proposing a Data Union strategy that ‘will, among other measures, explore the development of Data Labs as integral components of the AI Factories, to enable the provision, pooling, and secure sharing of high-quality data.’
It’s reasonable to be sceptical of sufficient follow-through on these recommendations, as was the case recently with the Draghi report. I’m naive enough to believe this period is different.
It has to be.
4. Breakout Consumer Agents In China
As I’ve written before, some of the world’s biggest consumer AI apps after ChatGPT are in China. Meta buying Manus (originally HQ’d in Beijing) is an indication of the cutting-edge agent harnesses being built in China.
The antecedents of China’s hyper-competitive market are too lengthy to labour on here, but the resulting environment is one that is: heavily oriented towards consumer apps, big tech are constantly entering new business lines and competing with each other, business models are heavily reliant on advertising rather than subscriptions.
Upcoming IPOs of labs like Z.ai and Minimax and competitive model releases from companies like Xiaomi are consistent with China’s focus on efficient models that can run on devices (and, importantly, in factories).
Freda Duan wrote about the impressive Doubao Mobile Assistant from ByteDance in December:
The key idea: “operating-system-level collaboration between Doubao and mobile phone manufacturers.”
Meaning: this is not a standalone app. It is a system service baked into the ROM, able to drive the UI like a human across apps, mostly via real-time voice.“Find which KFC spicy chicken burger is cheaper on JD vs Meituan vs Taobao, pick the lowest price, deliver to X address, add note ‘leave at front desk,’ then screenshot the order and send to A on WeChat.”
The agent literally opens and navigates multiple shopping apps, compares prices, and completes the entire workflow.
There’s been lots of speculation around whether Google would lean into Pixel more heavily as they would also be well placed to deliver this kind of experience. As Apple’s struggles continue, it might be a Chinese company that sets a new high watermark of consumer agents.
5. Memory Cracked And Portable Context Wars
‘Sign in with OpenAI’ has been a long time coming, given the rich semantic and behavioural data collected in the last three years.
These ‘behavioural signatures’, as my friend Antoine Moyroud described them, could unlock radically better personalisation in software:
Logging into a new tool will no longer feel like introducing yourself from scratch but more like picking a memory provider that brings your context with you. Your preferences, tone, goals, personality, all imported with a simple click.
The exact architecture for how memory will be stored, updated, and accessed is still being refined, with different approaches representing different trade-offs.
Google introduced ‘test-time memorisation’ in December, a way for new ‘surprising’ inputs to be stored in long-term memory. I expect to see more developments like this that go beyond improved summarisation of past conversations.
The portability of context/memory is contentious as in theory it’ll reduce switching costs for consumers. The labs will continue erecting walled gardens around the metadata they’ve collected on you, allowing you to use it to onboard onto new software but not export the raw data. New UI paradigms will emerge for how consumers manage their memory repos.
Open Questions for 2026
Will AI app markets start consolidating? Legal, healthcare, finance and several other end markets are heavily capitalised with efforts to kingmake doing little to restrict more capital flooding into these markets. The same can be said for markets like customer support and go-to-market software. We’re 1-3 years in for several consensus categories - will 2026 be the year of culling as the winners pull away (defined as companies with durable revenue, talent vortexes, and early upmarket penetration, among other things)?
Will credit funds continue financing the AI infrastructure buildout? The scale of capex today has already far surpassed the free cash flow thrown out by big tech. There have already been signs that the reliance on external capital may be untenable.
Will operating leverage hold as the 2022/2023 class of AI companies continue scaling? To date, the best AI companies have crushed the leading software companies of the past decades when it comes to metrics like ARR per FTE, OpEx per FTE, and so on. How will these numbers hold up as they scale?
Will new distribution channels gain traction? Founder-led content has helped companies like Lovable break out of a noisy market by building a brand directly with users and potential hires. Products with a prosumer motion might yet iterate on ways they can leverage AI more effectively, e.g. for demos. In the enterprise, if the role of an FDE will continue, how will it evolve and become more specialised?
What questions are you thinking about? Shoot me a note.
Signals
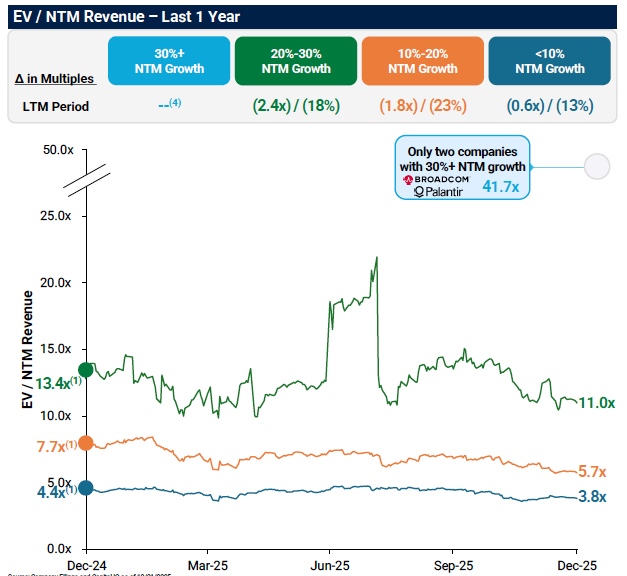
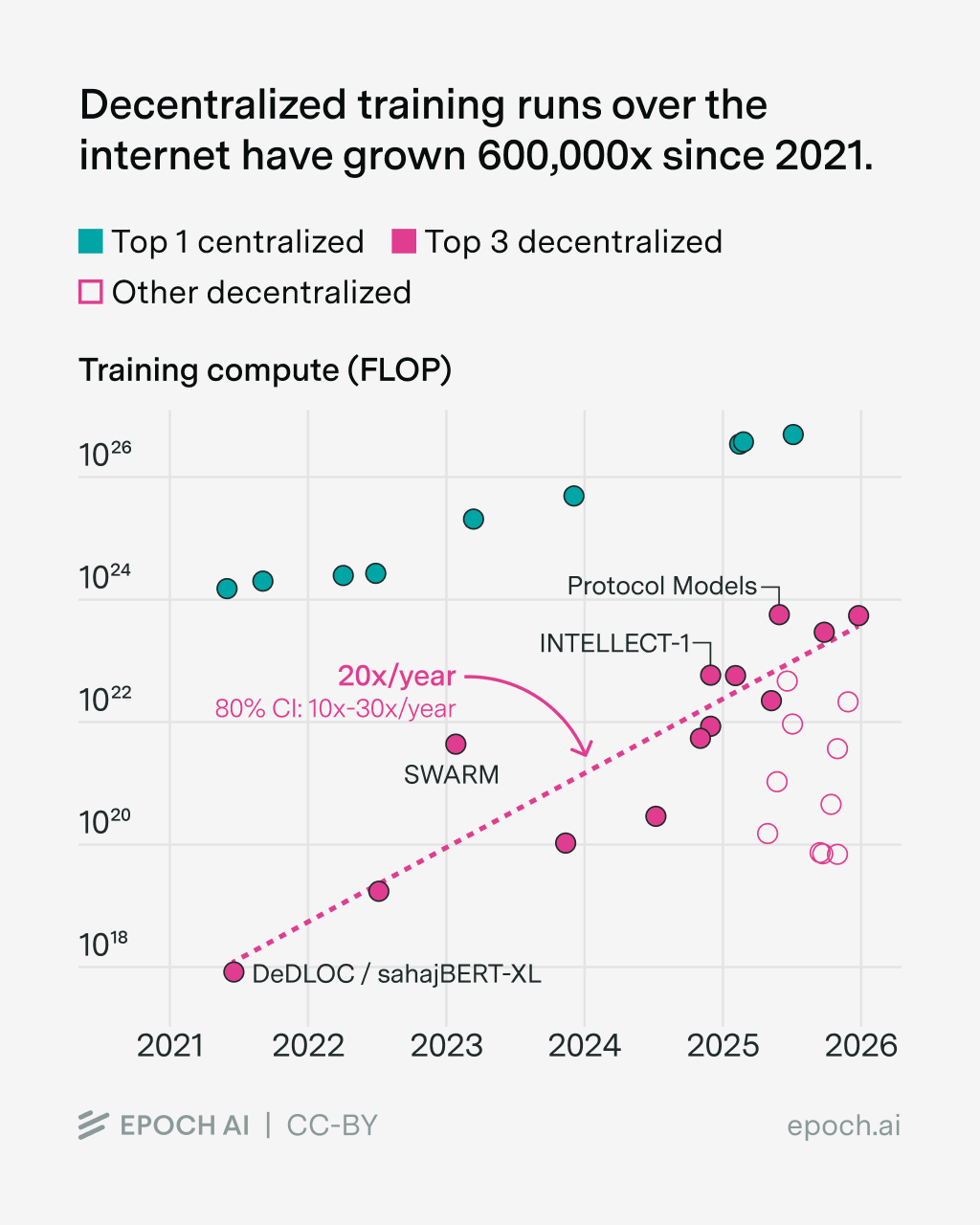
What I’m Reading
Portable Memory & Behavioral Signatures: the missing layer for AI personalisation
2025 Letter by Dan Wang
2025 Letter by Zhengdong Wang
Earnings Commentary
‘But most of the time, we’re taking just a piece, either we’re taking one full stack and then we’re going to take more stacks over time or we’re just taking maybe a horizontal slice of the stacks.
And so the opportunity for us exactly, as you said, is a continued stacking of, in a good way, a multiyear steady trend in terms of just doing more and more with each of these merchants ‘
Jeff J. Hoffmeister, Shopify CFO, Nasdaq Investor Conference
‘Copilot is for AI like the iPhone is for personal computing or like Windows was for the PC. It’s a platform... Agents are basically like the apps on your iPhone.’
‘We turned on Agent 365 before we launched and announced the product. And we have 138,000 agents being used by 88,000 employees on a weekly basis, which I would offer you all up to turn on Agent 365, it’s free in your environment because I would be willing to bet you have more AI happening inside your organization than you know about.’
Judson B. Althoff, Microsoft VP, Barclays 23rd Annual Global Tech Conference
Have any feedback? Email me at akash@earlybird.com.
Hi Akash! I think the trend I found most interesting is that enterprises shop for model check points to ensure their tools are more accurate thus reducing hallucinations. This ensures that a firm's proprietary data is embedded as part of core training data. We will see this in areas such as healthcare, legal and finance where precision is valued and error is costly.