

The Future Of Compute
Nvidia, ASICs, Compilers
Software Synthesis analyses the evolution of software companies in the age of AI - from how they're built and scaled, to how they go to market and create enduring value. You can reach me on LinkedIn and X..
Roundtables
March 5: The Future of Software Engineering with Anthropic
Last week, we hosted a roundtable on the future of AI compute with Michael, CEO of Spectral Compute, who have built a compiler that compiles CUDA source code directly to native machine instructions for non-NVIDIA GPUs. We were joined by attendees from Graphcore, Cerebras, DeepMind and more.

1. Nvidia’s Monopoly Position
Michael opened by framing the current state of AI compute as a “monopoly moment.” Key points:
Nvidia controls 80%+ of datacenter GPU market share and briefly touched $5 trillion in market cap.
Their dominance stems from a head start in accelerated computing that dates back to CUDA’s first release in 2006–2007. Nearly two decades of consistent innovation in parallel compute has created an entrenched ecosystem.
Although open-source alternatives exist (e.g., Kronos Group standards, which Nvidia itself co-chairs), none approach CUDA’s adoption or defaultness.
There are now hundreds of millions of lines of CUDA code in the wild. Developers have built deep expertise around CUDA over years, creating massive switching costs. Michael’s analogy: convincing the world to drop CUDA is like convincing everyone to adopt the UK power plug — technically superior, but practically impossible.
2. Why Vendor Optionality Matters
Michael argued that having alternatives to Nvidia is critical for multiple reasons beyond just cost.
Cost Leverage
Nvidia was selling H100s at roughly 10x manufacturing cost, enabled by their monopolistic position.
These margins are unsustainable long-term, but the market hasn’t corrected because of ecosystem lock-in.
Supply Chain Resilience
Single-vendor dependency carries severe supply risk. When Nvidia misses production targets or its suppliers slip, customers are stuck.
Worst-case wait times for latest Nvidia compute are 18+ months.
Geographic prioritisation compounds the problem: North American customers get served first, APAC gets deprioritised, and Middle Eastern customers wait until policy deals are brokered.
Geopolitics
Compute allocation has become a geopolitical instrument. Where you sit geographically determines your access to cutting-edge chips.
3. Current Challengers and the Competitive Landscape
Michael surveyed the emerging alternatives to Nvidia:
AMD Instinct Series
Architecturally the most similar chips to Nvidia’s GPUs. The Instinct MI300 series is shipping, with the MI4XX series announced.
Meta signed a deal with AMD to deploy 6 GW of Instinct compute by end of 2027 — a massive commitment, though execution remains to be seen.
AMD GPUs are generally ~30% cheaper than equivalent Nvidia hardware, but people still aren’t switching en masse due to software incompatibility.
Cerebras
Cerebras’ wafer-scale engine draws ~27 kilowatts but is more efficient on a per-token basis at scale.
Cerebras announced a 500–750 MW deployment partnership.
Crucially, Michael noted that Cerebras’s chip is not an ASIC — it is programmable and general purpose, which he considers a wise design choice nowadays.
Google TPUs
TPUs are not purchasable outside of Google Cloud Platform; they are fully vertically integrated. You access them via GCP subscriptions.
Programming model is fundamentally different: systolic arrays with data-flow architecture rather than traditional threads/warps.
Writing kernels for TPUs works differently — there aren’t traditional kernels.
ASIC-Based Startups
There are ASICs focused on transformers like Etched, Positron and even Taalas who baked the transformer architecture into chip-level design, claiming speeds like 17,000 tokens per second.
Michael was critical of this approach: baking in transformer-specific logic creates the same depreciation cliff seen with Bitcoin miners (90%+ depreciation within 16–18 months).
He questioned the practical utility of extreme token speeds: “Your coding agent is going to ask you dumb questions a lot faster” — the model quality running on these chips matters more than raw throughput.
Current speeds on 8B models might scale to 250B+ models in the future, making specialisation worthwhile.
Michael’s response: AI innovation is outpacing chip tape-out timelines. The field hasn’t settled on a final architecture — the transformer itself may be disrupted. Betting silicon on a fixed architecture is premature.
Other Notable Mentions
Next Silicon (Israeli) — Michael was most enthusiastic about their approach: they’ve etched the selection DAG part of a compiler into the chip, a novel architectural choice.
Axelera AI (European, embedded/small-scale inference)
Michael referenced a list of ~50 startups globally attempting to build AI chips.
Microsoft Maia
Microsoft launched Maia with an SDK access request form. Michael noted he still hadn’t received his SDK access, suggesting the chip may have incurred into delays.
4. The Depreciation Problem and Programmability
A substantial debate emerged around chip depreciation and what it means for investment decisions.
The Financial Reality
H100 chips launched at $40k per chip; a single node costs $400k+.
These are not disposable assets — buyers need confidence the hardware retains value beyond a one-year cadence.
Bitcoin miners depreciate 90%+ within 16–18 months, creating a cliff that makes planning impossible.
Cerebras
If CUDA is truly so powerful and versatile, why does hardware depreciate so fast? In theory, CUDA’s universality should let you keep running older chips (e.g., multiple A100s instead of one H100).
Michael’s response acknowledged the tension:
Nvidia has a financial incentive to drive new GPU purchases — they make money on new silicon, not on customers reusing old chips.
There’s deliberate market segmentation: Nvidia explicitly wants H100s in certain deployments and not others. They don’t even use the term “heterogeneous” for their own chip generations.
Additionally, hardware constraints make simple substitution impossible: precision (FP) differences between A100 and H100, and capped InfiniBand on A100s mean you can’t just swap older interconnects with newer ones for large-scale training.
The Core Argument
Michael’s central thesis: programmability and general-purpose capability are the most important chip design attributes because they preserve long-term value as workloads evolve. Application-specific chips face existential risk from architectural shifts in AI.
With tape-out costs at $20–30M minimum and 2–3 year chip lifecycles, a startup raising $100M gets essentially one generation of silicon. If the AI landscape shifts (e.g., mixture-of-experts changing distributed compute patterns), an architecture-specific chip is stranded.
5. Spectral Compute
The CPU Analogy
Michael explained the problem by contrasting CPUs and GPUs:
In the CPU world, you write code once and it runs on AMD, Intel, or ARM without modification. You pick hardware on merits (price, performance, cache) without rewriting your software.
This freedom does not exist for GPUs. Switching from Nvidia to AMD requires porting code, despite the chips being architecturally very similar. AMD calls thread groups “waves” where Nvidia calls them “warps” — substantively the same thing, but different enough to break compatibility.
The Spectral Approach
Embrace CUDA as the de facto standard rather than trying to replace it.
Let developers write CUDA code, pipe it through Spectral’s compiler, and have it compile directly to AMD native instructions (and eventually other architectures).
This is not transpilation — it’s ahead-of-time compilation that goes all the way down to native hardware instructions, enabling deep optimisation.
Developers can still hyper-optimise for specific hardware via #ifdef blocks for particular devices, but the default path works across all supported GPUs.
Why Direct Compilation Matters
AMD’s CUDA equivalent (HIP/ROCm) is frustratingly different in subtle ways that break programs and is also slower in many cases.
Transpiling to HIP would lose optimisation opportunities. By compiling directly to AMD native instructions, Spectral can reason about the full pipeline from high-level CUDA to transistor-level operations.
A specific example: AMD uses opposite column/row format for tensor operations compared to Nvidia. Spectral’s compiler can detect this, prove that reordering is safe, and perform the transformation at compile time with zero runtime overhead.
Performance Results
Spectral showed benchmarks comparing their compiler against AMD’s HIP toolkit. In several cases Spectral outperforms AMD’s own software stack; in others there’s room for improvement on both sides.
They also compared against OpenCL: on Nvidia, OpenCL is behind; on AMD, it’s roughly on par. But there’s limited OpenCL code in the wild to benchmark against.
Coverage Status
Michael showed their current CUDA API coverage, prioritised by real-world usage. Core CUDA APIs are substantially covered, including GrowMax operations.
PyTorch support is their key milestone: early builds expected mid-Q2 2025. This is significant because PyTorch exposes nearly all low-level CUDA APIs to Python, so supporting it effectively means comprehensive CUDA coverage.
Business Traction
Most traction currently in academia — researchers using some of the world’s biggest supercomputers.
Working with a consortium of premier motorport teams on safety applications.
Engagements in HFT/algorithmic trading.
Goal for next 12 months: serious deployments with large AI labs and adoption by neocloud providers as the standard portability layer.
Team and Hiring
22 people, remote-first, clustered around Europe (6 in greater London, 4 in Edinburgh, 3 in the Netherlands, 2 in Greece, 1 in Denmark, 1 in Italy, co-founder in California, 1 in Singapore).
Talent is extremely scarce: people who are both GPU architecture experts AND compiler specialists number roughly ~200 globally. Spectral recruits from universities and cross-trains.
Open Source Strategy
Not currently open-sourcing the core technology. The “coup de grâce” is their vendor-neutral compiler optimisations, which they consider proprietary IP — “for the same reason Nvidia isn’t open-sourcing theirs.”
6. AI-Assisted Compiler Optimisation
A notable exchange occurred around AI’s role in GPU code optimisation.
An attendee noted his team went from two months to two weeks of optimisation using AI-assisted coding tools at low-level GPU programming.
He questioned whether traditional compilers could ever make the leap from naive attention to Flash Attention — something that took human researchers two years to develop.
Michael’s view: the compiler “just isn’t smart enough yet” — nobody has written compilers to fully exploit GPU architectural possibilities. That’s a core part of Spectral’s R&D.
He argued AI-assisted code generation will eventually outperform human hand-optimisation because it can brute-force search a much larger space of possible programs. Combined with fast correctness verification, this creates a direct path to highly optimized code.
Importantly, that optimised code should be written in CUDA (not HIP or another niche language), for the same reason LLMs are better at English than Danish: the training data corpus is vastly larger.
7. The Cloud Hyperscaler Lock-In Dynamic
Discussion turned to how cloud providers are compounding the vendor lock-in problem:
Google, Microsoft, and Amazon each want to control the full vertical stack — custom chips, custom SDKs, and proprietary APIs.
Once customers build on a hyperscaler’s fully integrated stack, switching costs become prohibitive (similar to AWS’s original API lock-in playbook).
The landscape will fracture further, not consolidate. Unlike the CPU world (Intel, AMD, ARM — three similar architectures), the GPU/accelerator world could see 20–30 different architectures.
Each hyperscaler’s new chip generation introduces architectural changes, deepening incompatibility.
This trend is likely to intensify as the industry shifts from training toward inference, where specialised inference chips from each hyperscaler will capture more market share.
8. Training vs. Inference Shift
A significant data point emerged in discussion:
60%+ of total compute used to train foundational models is now post-training (reinforcement learning), not pre-training. The pre-training dominant era is over.
This RL-heavy workload can be disaggregated across data centers but still faces throughput constraints between clusters.
This shift has implications for chip design and data center architecture — different workloads may favour different hardware configurations.
9. Data Center and Infrastructure Constraints
Cooling Capacity
Cerebras’s wafer-scale engine draws 27 kW. Regardless of chip vendor, liquid cooling and high-power infrastructure is inevitable.
However, the buildout is slow: companies like Cloudflare with hundreds of thousands of PoPs globally can’t upgrade all sites simultaneously.
Meanwhile, the most common PCIe inference card (H100 NVLink) fits standard 600W PCIe slots. Nvidia hasn’t even updated this form factor for Blackwell. There’s an underserved niche for inference in existing data center infrastructure.
Multi-Data-Center Training
It was noted that if you can link H100s across two data centers via high-bandwidth interconnects, you can approximate the performance of newer GPUs without ripping and replacing.
Michael agreed this works for some workloads that can be disaggregated, but not all.
10. Key Debates and Open Questions
Will Nvidia’s Dominance Erode Through Interoperability?
Developers won’t switch because alternatives aren’t faster; alternatives can’t get faster without developer adoption.
Michael’s answer: some large players (Meta with AMD) are making the leap. Spectral’s role is to be the “universal Babel translation layer” that removes the switching cost entirely. Their roadmap includes supporting AMD’s ROCm libraries on Nvidia hardware — enabling developers to use the best of both ecosystems on either vendor’s chips.
Groq and Nvidia’s Acquisition
Nvidia acquired a non-exclusive IP license to Groq’s core technology and hired their CEO and senior staff in late 2024. The deal was characterised as more than 3x Groq’s previous valuation, effectively an “acquihire” structure.
GPU Utilization Gaps
There’s research showing traditional kernels only use 40–50% of Nvidia GPU compute capacity, largely due to memory-bound bottlenecks.
Michael framed this as an algorithmic optimisation problem with multiple attack vectors: data compression, hardware changes, and compiler improvements. No single approach solves it universally.
Nvidia’s tensor cores are themselves an example of the hybrid approach: an ASIC-like unit embedded within a general-purpose programmable chip.
The Cisco Networking Analogy
There’s a parallel to Cisco’s networking dominance: Cisco created an entire certification ecosystem that made switching to Arista painful. However, customers with extreme performance needs (e.g., low-latency trading) will always seek alternatives.
Cerebras signed with OpenAI specifically because OpenAI couldn’t achieve >1,000 tokens/second inference with other hardware and needed breakthrough performance.
Signals

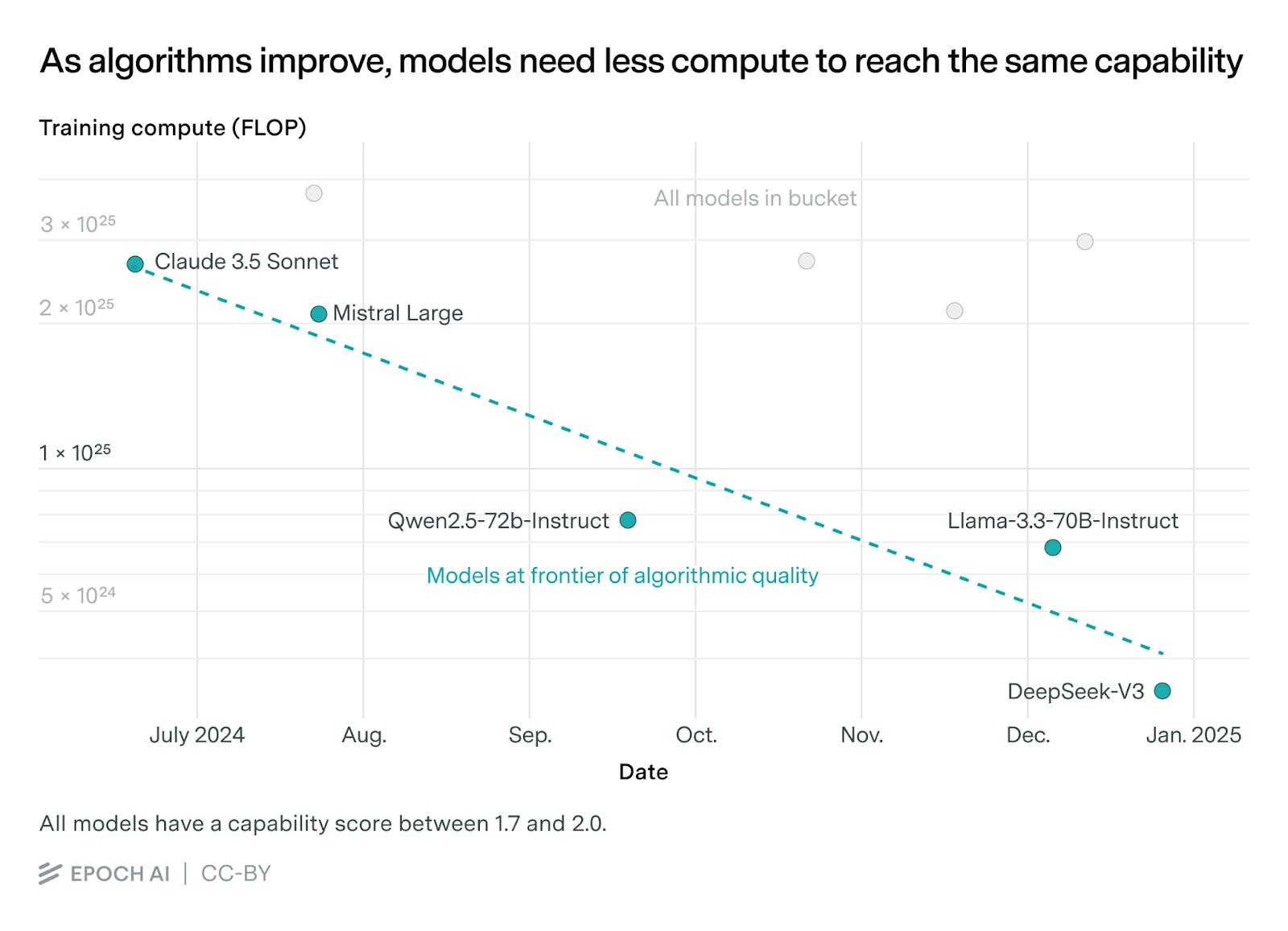
What I’m Reading
A Level Headed Look at State of Software
Earnings Commentary
Agents also need to love MongoDB. That requires us to ensure that we have all the right integration with the right places, how we auto scale, how we ought to perform during the peaks and valleys. All of that truly needs to be autonomous and driven by machines. And that requires absolutely the focus from the engineering team that how would machines look at this if they want to provision an additional node or if they want to manage cluster because of resiliency across multiple clouds. So that will be the North Star for us that our agents will love MongoDB as much as today, human developers love MongoDB.
Chirantan Jitendra Desai, President & CEO MongoDB, Q4 FY2026 Earnings