

The Evolution Of Enterprise Software
Systems Of Records And Action Give Way To Agentic Systems

Software Synthesis analyses the evolution of software companies in the age of AI - from how they're built and scaled, to how they go to market and create enduring value. You can reach me at akash@earlybird.com.
A recurring theme I’ve written about is playbooks founders can use to displace systems of record (SoR) and capture the hundreds of billions of collective enterprise value across categories like the ERP, CRM, HCM, and ITSM.
The first of these essays covered how to integrate and surround systems of record by starting as a system of action (SoA) and informing your product roadmap by studying the utilisation of modules across the SoRs product portfolio (attacking the modules with the lowest utilisation first).

The second of these covered how multi-product companies become platforms of compounding greatness (h/t Tidemark) by launching new products that acts as multipliers and establish the advantages of a highly integrated suite.
We then explored how systems of action reduce data deficits in the age of AI through a combination of new types of data being generated and data partnerships.
A friend recently asked me:
Do SoAs aggregate enough data / metadata themselves to earn some degree of local SoR status?
Or, is the stickiness less down to any data gravity of their own and more of a function of workflow/habituation than anything else?
Do all systems of record start as systems of action?
Are the well known SoRs systems that employees once lived in to a far greater degree?
Are there any examples in recent memory of de novo startups going directly for incumbent SoRs and successfully displacing them?
Let’s dive in.
Systems of action relative to Systems of record
A SoR is the authoritative data source of truth for a particular business entity or process. Key canonical data types owned by SoRs include things like Customer IDs (in CRMs), Employee IDs (in HR systems), or General Ledger entries (in accounting/ERP systems).
The stickiness comes from the nature of this data. The canonical data in SoRs is a unique identifier referenced by every other application, so it anchors the entire enterprise data graph. All downstream SoAs need to refer back to Customer IDs, Employee IDs and GL entries.
The incumbent SoRs were founded decades ago in prior technology paradigms when the primary goal was accurate record-keeping (particularly in the case of ERPs).
The Pre-Web era cohort didn’t need to build software that had high engagement and workflow density, as users were simply maintaining databases. The client-server era was no different, as PeopleSoft (1987) and Siebel (1993) were still primarily treated as databases.
The Web era after 1999 represented the beginning of the ‘consumerisation’ of enterprise software as real-time collaboration became possible and users began to demand consumer-grade UIs.
The cloud-native era saw the PeopleSoft founders found Workday in 2005 as the new cohort of SoRs continued innovating on consumer-grade experiences, real-time updates, and elastic scalability.

As to whether employees lived in incumbent SoRs to a greater degree in the past, it’s a continuum.
The post-web era SoRs had to build workflow automation/collaboration as these became table stakes for software at the time, whereas the SoRs founded in the mainframe and client/server days were explicitly set up to be databases for record-keeping.
In that sense, the post-web era SoRs started out as SoAs relative to the prior generation of SoRs, by building in properties that were demanded by employees entering the workforce as the internet and cloud took off.
The new AI-native SoAs vying to become SoRs are simply a continuation of this trend - they’re internalising AI capabilities at a faster clip than prior generations as those are the default expectations of employees entering the workforce today.
Data Gravity or Workflows?

The value of data in SoR/SoAs has increased over time as new capabilities were unlocked. Now, with AI agents, enabling automation is the north star for enterprises.
The data gravity of canonical SoR data has become vulnerable as LLMs make data migration a fraction of the effort it used to be. Startups will hope, though, that data doesn’t become too fungible, as then they’ll be vulnerable too!
Ironically, it’s probably better for this GTM if the cost doesn’t go down too much. The difficulty of migrating SoRs leads to low churn rates and high LTVs, which justifies the investment in doing the migration work as a vendor — but if migration costs drop too far, others can do the same to you; churn will tick back up, meaning LTVs drop, and soon you’re in a race to the bottom. Data viscosity is your friend, until it isn’t.
Metadata generated by SoAs has historically been seen as asserting less gravity and retentive behaviour from customers, but that’s been changing for a while. AI has only accelerated this transition.
The data emitted by SoAs is high-volume and behaviour-rich. Foundation models thrive on volumes of unstructured data it can ingest from SoAs like Gong/Granola’s call transcripts or Ramp/Zip’s transaction data. Compared to static data residing in SoRs like customer ID, account status or next meeting date, the data generated by SoAs is far more valuable to drive automation using AI agents.
As such, SoAs do indeed benefit from a consolidation of workflows/habituation and datasets accumulate as a byproduct of this. In the past, humans needed the ‘single source of truth’ data stored in SoRs to instrument a range of applications on top of SoRs. The present and future world values the data being generated in SoAs more highly, as its this data that powers the effectiveness of digital workers.
That being said, data infrastructure and lakehouse vendors will claim that enterprises should stored all kinds of data (structured, unstructured) with them, as we’ve covered in the past. Surveys with CIOs suggest that’s where we’re headed directionally, which means the SoAs that will thrive will focus less on data gravity and more on product R&D that drives engagement.
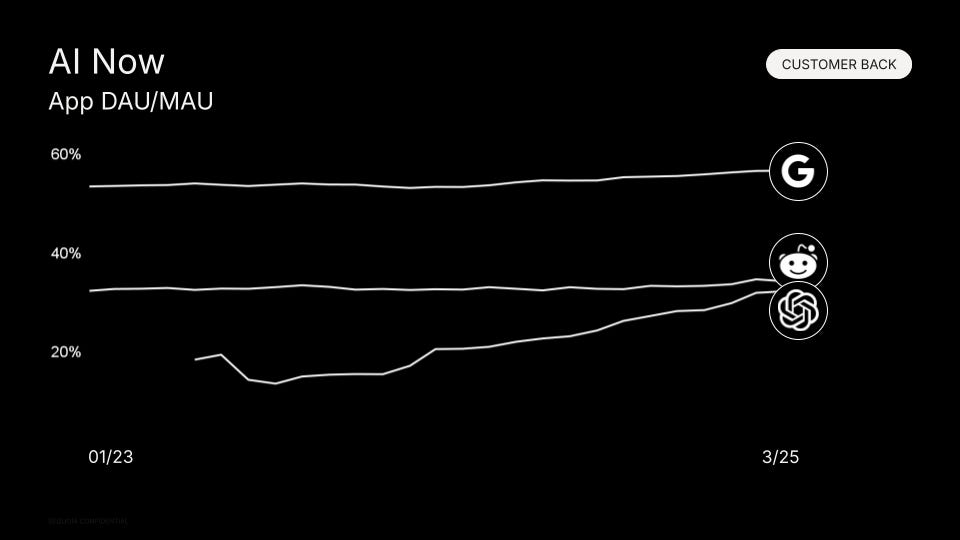
The good news is that AI apps are catching up to the engagement levels of the very best internet companies. I don’t have the same data for Cursor, Lovable, Bolt or Granola, but I’m confident they’re trending in equally promising ways.
Blurring lines
As we’ve touched on, all application software companies store data of some kind. The data stored in SoRs has historically been more important than other types of data, but that’s changing. If we look back over the history of application software, there are several successful examples of companies accruing datasets that have SoR/SoA-like properties.
Hubspot
At the time of its IPO in 2014, Hubspot was unique in having gotten to IPO scale with its SoA wedge, marketing automation. It’s CRM, or SoR, was launched the same year and is now worth hundreds of millions.

Rippling
Rippling started with a SoA wedge of employee onboarding before becoming a full blown HCM that includes canonical employee data.
The product sequencing was informed by the path that would allow Rippling to hoover up all HR and IT-related data pertaining to employees and their devices, a classic case of integrating and surrounding the incumbent HRIS which would have hardly any unique data left.
The company’s already on its way to executing the same strategy for the Finance function.
ServiceNow
ServiceNow started as a SoA company serving IT help desks with workflow automation, before expanding to classic SoR categories like CRM.
Before expanding into CRM, though, ServiceNow had also become the SoR for configuration item data, encompassing all kinds of IT assets servers, VMs, network devices, and SaaS apps.
ITSM tickets are the exhaust of the SoA but eventually powers downstream SoA products for incident response like PagerDuty, and so can also be deemed SoR data.
Further examples
Corporate card and spend management companies have built unified product suites that still pipe data into ERPs. Finance teams live in Brex/Ramp, yet still need to close their books in NetSuite or Xero. AI agents will be powered by both accounting entries and the rich transaction and purchase order data sitting in AP/AR products.
Atlassian’s Jira transitioned from a SoA to a SoR for software development. Github and Gitlab are both SoRs and SoAs.
Directly displacing SoRs
Most companies looking to displace SoRs approach it with the integrate and surround sequencing strategy, especially in the enterprise where the cost of ‘rip-and-replace’ is highest.
Startups going directly after SoRs from the early days are likelier to succeed selling into other tech companies, from startup to scaleup. As the data reveals, this can already get you to meaningful scale, at which point your product is likely to be deemed more enterprise-grade and the costs of migration for enterprises become worth bearing.
AI represents a window for startups to capture budgets allocated to SoRs and deliver agentic systems instead. Businesses want outcomes, not tools. Software is the business of selling promotions.
If an agentic system can perform a task reliably, businesses will care a lot less about whether a Customer ID is stored in a ‘CRM’ or in their data lakehouse, as it won’t be humans querying the database but rather agents.
The whole premise of a SoR was conceived in prior technology shifts when record-keeping and employee productivity were paramount. This new shift calls for a first principles reassessment of what constitutes valuable software for a customer.
Interesting Data





Jobs
Companies in my network are actively looking for talent - if any roles sound like a fit for you or your friends, don’t hesitate to reach out to me:
Granola is hiring infrastructure, product and AI engineers (London).
Marbl, a vertical SaaS solution for Medspas founded by Revolut alum, is hiring front, back-end and ML engineers (London).
Briefcase, a seed-stage vertical AI company building in accounting, is looking for Founding Product Engineers (London).
SpAItial are building 3D foundation models and are looking for a Research Engineer, Research Scientist and Software Engineer (London or Munich).
If you’re exploring starting your own company and are looking for a cofounder, please reach out to me at akash@earlybird.com - I’d love to introduce you to some of the excellent talent in my network.
Loved this! Based on thesis, at least initially it seems there’s going to be a lot of incentive for compliance heavy industries and startups working in that segment to build these SoA and have really good growth.
Excellent systemic and granular view of technology evolution leading to agentic orchestration.