

Nvidia: Process Power
Speed of Light

Hey friends, I’m Akash! Software Synthesis analyses the evolution of software companies in the age of AI - from how they're built and scaled, to how they go to market and create enduring value. Join thousands that are building, scaling, or investing in software companies - you can reach me at akash@earlybird.com.
Last week's GTC once again affirmed that Nvidia's competitive advantages aren’t rooted merely in vertical integration, but in their operational excellence and speed of execution - traits that in the Hamilton Helmer lexicon would be their process power.
Prefill and Decode
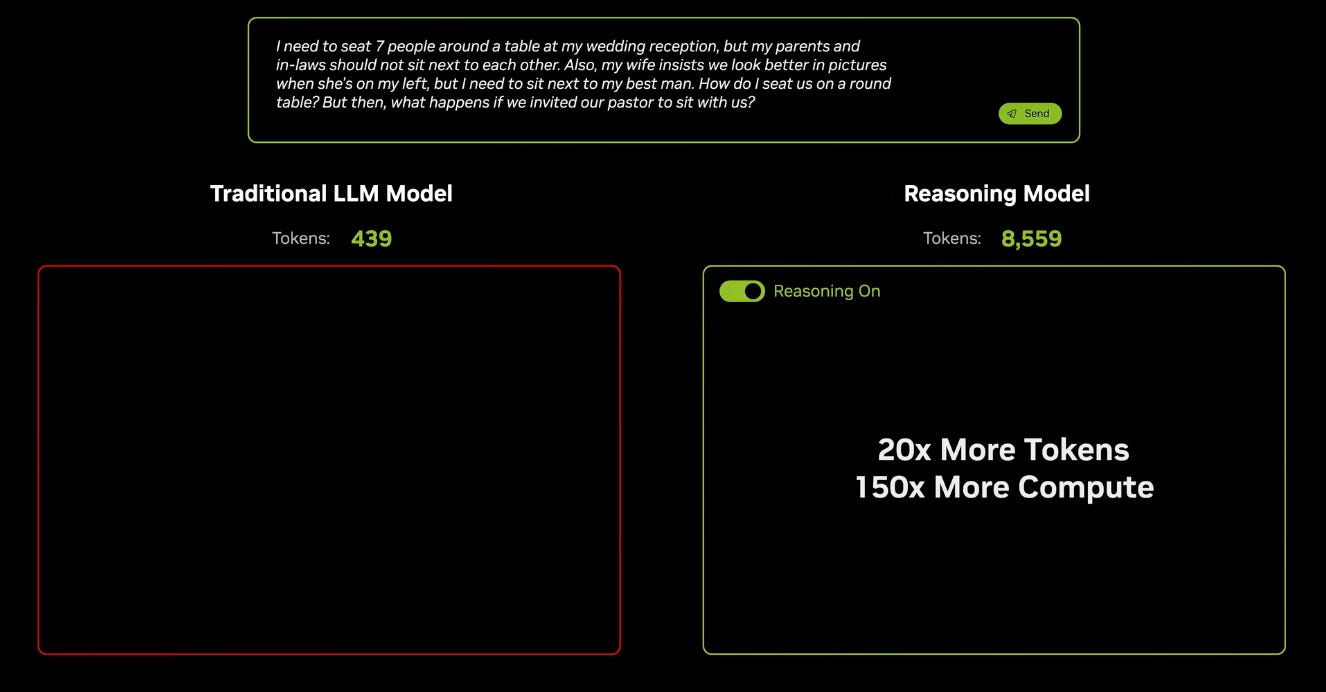
The threat of distillation to GPU demand in the post-R1 world is weighing heavily in the public markets, a concern that Jensen emphatically dismissed as he suggested demand for tokens is going to increase 100x in the test-time scaling paradigm.
, from outside the US +1-210-677-3788.")
Reasoning models ‘think’ by generating reasoning tokens - they create a plan, consume information from different data sources and synthesise the learnings before generating any outputs.
Here’s Jensen defining the prefill component of inference.
One of the phases of computing is thinking. When you’re thinking you’re not producing a lot of tokens, you’re producing tokens that you’re maybe consuming yourself, you’re thinking maybe you’re reading, you’re digesting information, that information could be a PDF, that information could be a website. You could literally be watching a video ingesting all of that at super linear rates and you take all of that information and you then formulate the answer, formulate a plan to answer, and so that digestion of information context processing is very FLOPS intensive.
Then comes the decode phase when tokens are generated for the end user, which requires the movement of huge volumes of data between High Bandwidth Memory and on-chip memory.
Whenever a transformer model generates a token:
It must access the full model parameters (weights and biases)
It must access the KV cache from all previously generated tokens
It performs a forward pass through the entire model
It generates a probability distribution for the next token
It selects the most likely token
It updates the KV cache with the new token's key and value vectors
It repeats this entire process for the next token
Companies like Cerebras are tackling this problem by designing ‘Wafer-Scale Engines’ that place SRAM memory directly adjacent to compute cores across the entire wafer. Nvidia’s NVLink, on the other hand, provides the physical high-bandwidth interconnect infrastructure that allows multiple GPUs to function effectively as a single massive GPU, unifying memory access through a shared memory system across multiple GPUs that allows any GPU to access memory from any other connected GPU with minimal latency (576 terabytes p/s bandwidth).
Where NVLink is the networking technology that connects GPUs, the newly unveiled Nvidia Dynamo is the software that orchestrates workloads across various combinations of prefill and decode ratios.
Why does this matter?
Well, the reasoning workloads of the future will vary.
Some will require more prefill (e.g. OpenAI’s planned PhD level researcher) whilst other workloads will be more decode-heavy (e.g. knowledge search across a company knowledge base). This is where the generalisability of GPUs is superior to the customisation of ASICs.
Jensen likens Dynamo’s abstraction of GPUs to VMWare's role in virtualisation:
I can dis-aggregate the prefill from the decode and I could decide I want to use more GPUs for prefill, less for decode, because I’m thinking a lot. It’s agentic, I’m reading a lot of information, I’m doing deep research. And then it goes off and it does all this research, and it went off to 94 different websites and it read all this. I’m reading all this information and it formulates an answer and writes the report, it’s incredible. During that entire time, prefill is super busy and it’s not really generating that many tokens.
On the other hand, when you’re chatting with the chatbot, and millions of us are doing the same thing, it is very token generation heavy, it’s very decode heavy, and so depending on the workload, we might decide to put more GPUs into decode depending on the workload, put more GPUs into prefill.
Well, this dynamic operation is really complicated. So I’ve just now described Pipeline Parallel, Tensor Parallel, Expert Parallel, in-flight batching, dis-aggregated inferencing, workload management and then I’ve got to take this thing called a KV cache. I’ve got to route it to the right GPU, I’ve got to manage it through all the memory hierarchies. That piece of software is insanely complicated and so today we’re announcing the Nvidia Dynamo.
Nvidia Dynamo does all that, it is essentially the operating system of an AI factory. Whereas in the past, in the way that we ran data centers, our operating system would be something like VMware and we would orchestrate, and we still do, we’re a big user. We orchestrate a whole bunch of different enterprise applications running on top of our enterprise IT. But in the future, the application is not enterprise IT, it’s agents and the operating system is not something like VMware, it’s something like Dynamo, and this operating system is running on top of not a data center, but on top of an AI factory…

, from outside the US +1-210-677-3788.")
Nvidia bears suggest that they’ll lose market share in a world that rotates away from predominately training workloads into inference workloads.
The releases last week position Nvidia to thrive in a world of heterogeneous workloads. No two inference workloads are the same.
This was of course just one release announced last week out of dozens.
Let’s move on to future generations of chips and where Nvidia’s process power becomes truly evident.
Keep Up If You Can
Nvidia’s velocity has been a hallmark of the company since its earliest years, as Tae Kim excellently chronicled in The Nvidia Way.
Before the launch of the RIVA 128 chip in 1997, Nvidia was on the brink.
It’s competitors like 3dfx thought they could pick up the company’s talent for cheap as bankruptcy looked nailed on. With their backs against the wall and 9 months of runway left, the company was galvanised into producing a leading consumer graphics chip much faster than anyone could have predicted - a sign of what was to come for the following three decades.
The RIVA 128 was the largest chip that had ever been manufactured at the time and to shorten quality-assurance testing timeframes, Jensen risked one-third of the company’s runway by buying chip-emulation machines from Ikos - this shaved off a year from the production process.
Nvidia was to unveil RIVA 128 in April 1997 at the Computer Game Developers Conference - the team had to work tirelessly to meet this deadline. PC manufacturers were to judge performance on 3D graphics benchmarks before making orders. Given the importance of this showcase for a company that would go on to be worth trillions, it’s hilarious to read how much luck played a role:
Our dirty little secret was the RIVA 128 would only run that particular test once and it did so tenuously.
RIVA 128’s success would go on to set off a domino effect where more capital was secured from Sutter Hill and Sequoia whilst great talent jumped ship to Nvidia (it’s worth reading the whole book).
Nvidia may well have not made it were it not for Jensen’s expectation that employees work at the ‘Speed of Light’ - outputs should only be constrained by the laws of physics. A former Nvidia executive was quoted in the book:
Speed of Light gets you into the market faster and makes it really, really hard, if not impossible, for your competitors to do better.
Later, in 1998, Jensen would apply these learnings to cement Nvidia’s future dominance of the chip market.
In discussions with Nvidia’s Head of Marketing, Jensen realised that chip companies were at the behest of PC manufacturers who operated on a semi-annual release cycle - each new release in the spring and fall needed new chips. Chip makers, on the other hand, needed much longer to design and launch new chips and only worked on one chip at a time. The demands of the PC market meant that no chip maker held market leadership for any prolonged period.
Realising this, Jensen decided to restructure the organisation to line up with refresh cycles of their customers.
Nvidia split the chip design team into three groups. The first would design a new chip architecture, whilst the other two worked in parallel to develop faster derivatives of the new chip. This way Nvidia could release a new chip every six months.
Another key technical decision was to develop a ‘resource manager’ that allowed Nvidia’s engineers to emulate hardware features and test new software. Finally, Nvidia also instilled the principle of backwards compatibility for its software drivers. This meant that even if there was a newer chip on the market that might be marginally better than the newest Nvidia chips customers bought, a new chip would only be months away and the existing ones would work with the backwards-compatible software drivers.
The technical decisions are of course also part of the company’s process power, but the more salient lessons for software companies are likely to be the design of the org structure and the culture of moving at the ‘Speed of Light’ towards new chip generations.
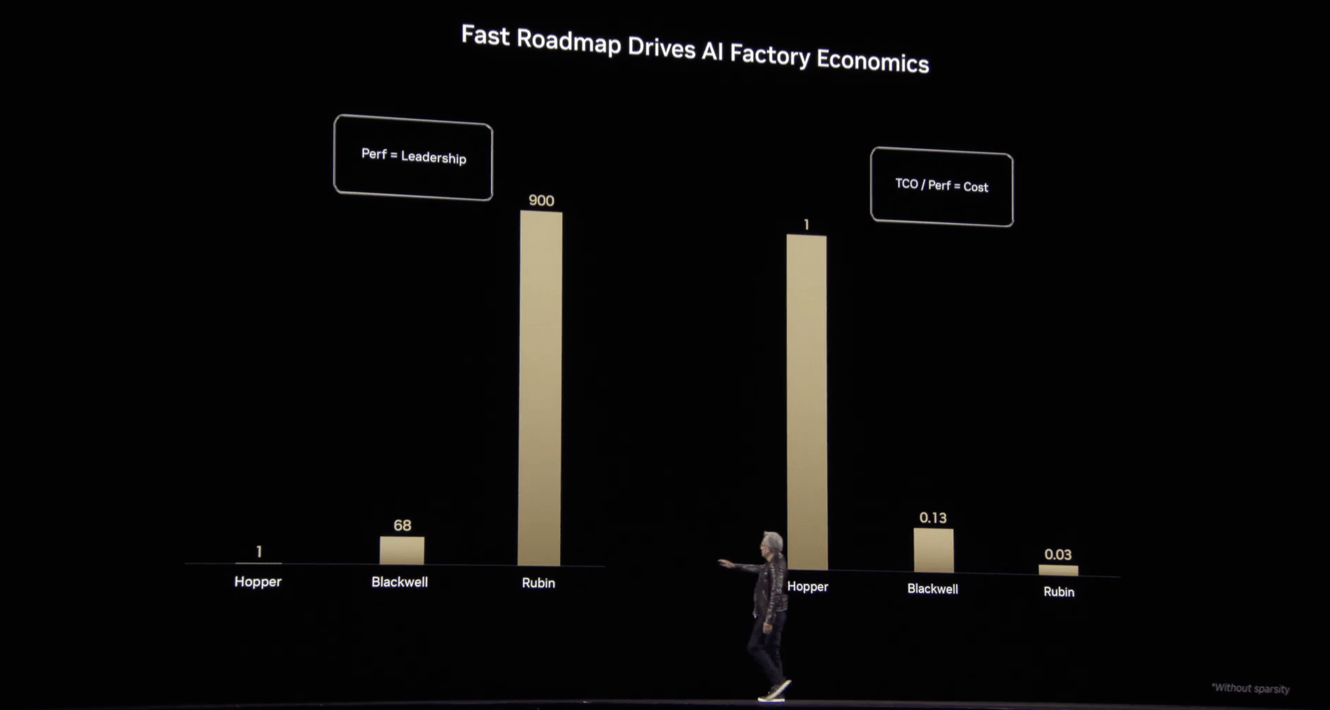
As Ben Thompson wrote, this process power makes even the ASIC efforts of the hyperscalers look futile:
That, though, means keeping up with Nvidia’s product development cadence; The Information has a post about Amazon offering instances using its latest Trainium ASIC at a significant discount to the H100. Huang, though, spent this keynote insulting the H100! You can almost hear him speaking to Amazon directly: you spent all this money, and are offering these huge discounts, just to entice developers to lock themselves into an inferior chip, even as reasoning models are going to swamp your available power generation.
At GTC Jensen even gave visibility to the Feynman generation of chips to come in 2028, which will be preceded by derivates of Blackwell and the new Vera Rubin generation. This pace of innovation for a hardware company is arguably one of the starkest examples of process power that we’ve ever seen.
Perhaps the analogous process power for software companies is how effectively they become compound companies.

Jobs
Companies in my network are actively looking for talent:
An AI startup founded by repeat unicorn founders and researchers from Meta/Google is building 3D foundation models and is looking for a 3D Research Engineer, Research Scientist and ML Training / Inference Infrastructure Engineer (London or Munich).
A Series A company founded by early Revolut employees is building a social shopping platform and is looking for Senior Backend, Frontend and Fullstack Engineers and Business Development Managers across Europe (London, Toronto, France, Germany, Spain, Italy, Remote).
An AI mobile app development startup is looking for their first Product hire (London).
Reach out to me at akash@earlybird.com if you or someone you know is a fit!