

Deterministic Inference: The Latency Tax
Another Pareto Frontier: Trading Latency for Determinism

Software Synthesis analyses the evolution of software companies in the age of AI - from how they're built and scaled, to how they go to market and create enduring value. You can reach me at akash@earlybird.com.
Gradient Descending Roundtables in London
November 12th: Small Language Models, Context Engineering and MCP with Microsoft Azure AI
November 18th: Agent Frameworks & Memory with Cloudflare
November 19th: Designing AI-Native Software with SPACING
There’s a new Pareto frontier defined by latency and determinism.
Elon Musk’s claim that diffusion-based LLMs will surpass autoregressive transformers comes on the heels of Inception Labs announcing a $50m to continue training their Mercury series of models that we first covered in March.
Time to first token is slower for diffusion-based language models but total generation speed is much faster.
Why does time to first token matter so much, though?
Fal cofounder Gorkem has a front-row seat powering image and video workloads for large enterprises:
Latency is really important. One of our customers actually did a very extensive AB test of like they on purposely slow down latency on file to see how it impacts their metrics. And it had a huge part in it. And it’s, it’s almost like page load time when the page load slower, you know, you make less money. I think Amazon famously did a very big AB test on this. It’s, it’s very similar. Like when you, when the user asks for an image and, you know, iterating on it, if it’s slower to create, they’re less engaged, they create fewer number of images and, and things like that.
Though slower to first token, thereafter diffusion models quickly eclipse autoregressive models:
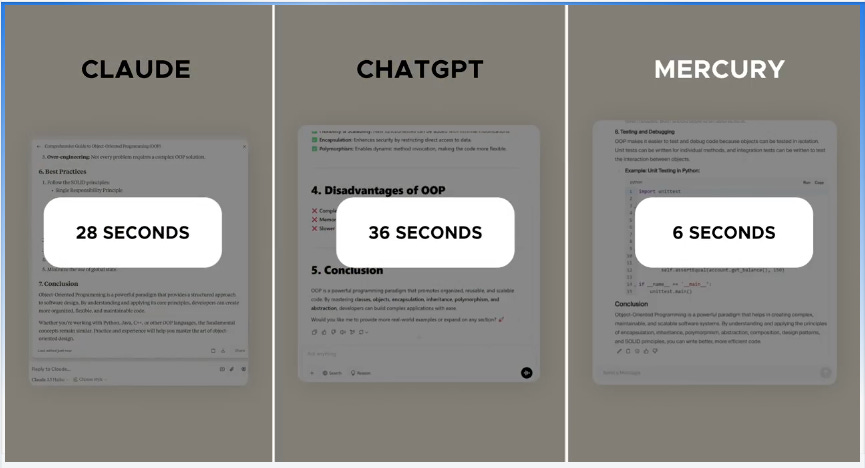
New research suggests diffusion language models achieve roughly 3x the data efficiency of autoregressive models - pretty handy as we hit data walls!
There will be plenty of workloads willing to trading off time to first token for total generation time and data efficiency.
Determinism is now attainable with the same trade-off.
Significant capital and talent has been focusing on how to provide the harnesses for language models to serve verticals and workloads that have low tolerance for hallucinations and inaccuracies - RAG and guardrails are just two of the resulting mechanisms.
In September, Thinking Machines Lab released their first product tackling non-determinism. At last, I got around to reading the accompanying paper.
Like many others, I had long assumed that the probabilistic nature of LLMs is intrinsic to the architecture of transformer-based language models.
On the contrary, this non-determinism is a property of GPU operations.
The wonderful property of parallel processing that makes GPUs so powerful for accelerated computing compared to CPUs is actually the culprit behind a lack of determinism.
A primer on how this works:
AI server load varies throughout the day
Batch size varies (for simplicity, imagine a batch size of 1 during quiet times, 32 during peak)
GPU kernel chooses algorithm based on batch size
Different algorithms sum numbers in different orders
Floating-point arithmetic makes addition order matter
Same input produces different outputs (nondeterminism)
Let’s unpack some of those concept.
Floating point non-associativity
Why do we use floating point numbers? Floating point maintains “significant figures” across wildly different scales.
Because it gives us “dynamic precision” - we can represent both:
Tiny numbers: 0.0000000486
Huge numbers: 3,450,000,000
The price is that addition order matters, because floating point operations necessarily lose precision and are order dependent.
GPU Kernels
At runtime, different orders are used for different batch sizes.
To illustrate, let’s imagine a smaller batch size at a quiet time of the day.
GPUs are optimised for parallelism, so for small batches they will use split-reduction to use as many cores of the GPU as possible. This is different to how larger batches would be handled, where sequential addition would be used.
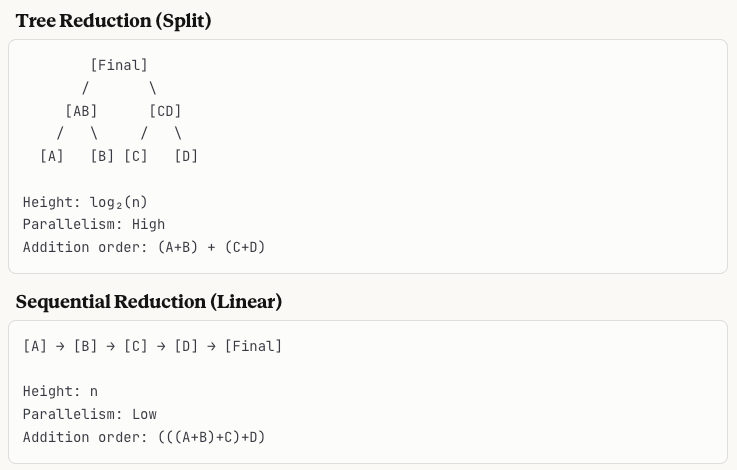
Thinking Machine Labs’ library proposes to resolve this by using the same reduction order independent of batch size, achieving batch invariance.
In doing so, parallelism and latency are traded off for determinism.
The results: Asked Qwen-3-235B “Tell me about Richard Feynman” 1000 times at temperature = 0
Without their kernels: 80 unique completions
Most common appeared 78 times
Divergence at token 103: “Queens, New York” (992x) vs “New York City” (8x)
With their kernels: 1 completion, all 1000 identical
The trade-off in latency is below.
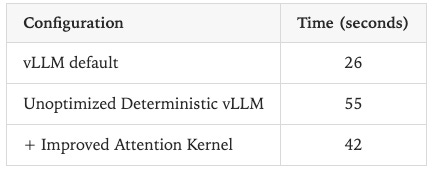
For enterprises in regulated industries, stuck in pilots waiting to move to production with their AI workloads, these trade-offs will be worth making..
Signals

What I’m Reading
The Evolution from RAG to Agentic RAG to Agent Memory
What does OSWorld tell us about AI’s ability to use computers?
Why behind AI: Data centres in space
Post Training Ensemble vs. Singular Model Approaches with Tinker
Earnings Commentary
During a period wheresome vibe coding tools are seeing slowing growth, Figma Make is speeding up. By the end of September, approximately 30% of customers spending $100,000 or more in ARR were creating in Figma Make on a weekly basis, and that number has continued to grow. We will continue investing heavily in AI, and we will trade near-term margin to build the right long-term platform for our customers.
Dylan Field, Figma Q3 Earnings Call
We have now onboarded thousands of customers to the Bits AI SRE agent. And as we prepare for general availability, we are getting very enthusiastic feedback on the time and cost savings enabled by Bits AI.
As RUM user recently told us, with Bits AI SRE being on call 24/7 for us, mean time resolution for our services has improved significantly. For most cases, the investigation is already taken care of well before our engineers sit down and open their laptops to assess the issue. And this is not an isolated comment. We see the potential here for our agents to radically transform observability and operations.
Olivier Pomel, Datadog Q3 Earnings Call
One thing that’s become quite evident is that power has become the bottleneck for everyone and power not only means access to energy, but everything underneath it in terms of infrastructure build-out, turbines, transformers, everything associated with generating power.
So in that environment, everyone wants to move to the most efficient compute platform as possible. Arm is about 50% more efficient than competitive solutions. We’ve seen that across the board in benchmarks, but also more importantly, in real-life performance. And that’s why we see NVIDIA, Amazon, Google, Microsoft, Tesla, all using Arm-based technology.
Rene Haas, Arm Q2 Earnings Call
Because our pricing model scales with the value we deliver, not with seats, our success grows directly alongside our customers. We price on a per profile, message and resolution basis, which lines up perfectly with the outcome-oriented business models AI is enabling.
Today, more than half of our ARR comes from multi-product customers, which is clear proof that customers want to have everything running off of one platform. This deepens our relationships with customers, improves retention and drives long-term growth
Amanda Whalen, Klaviyo Q3 Earnings Call
Have any feedback? Email me at akash@earlybird.com.
Great post . Does this imply that Chat GPT cannot do the same thing ?