Software Synthesis analyses the evolution of software companies in the age of AI - from how they're built and scaled, to how they go to market and create enduring value. You can reach me at akash@earlybird.com.
Join thousands of founders, operators and investors from the likes of Databricks, Stripe, Figma, and more
Last week we hosted MCP Part 2 with several members of the Anthropic research team, including David Soria Parra, co-creator of the protocol.
We had builders in the room from ElevenLabs, Google, Microsoft, Shopify and more. Building on last time's discussion, we managed to cover even more ground:
Despite concerns around security and authorisation, Anthropic is building classification systems, working with OAuth experts, and developing prompt injection detection. They're ahead of the problems, not behind them.
MCP currently leverages OAuth 2.1; future directions are to implement predictive scope mapping.
The Anthropic team is working closely with the community and developing the protocol, whilst sharing visibility on the roadmap concerning things like the public registry.
Stay tuned for the next one!
Context Engineering has been all the rage in the world of AI Engineering.
In the 6 weeks since Shopify CEO Tobi Lutke wrote that tweet, Langchain, Cognition, Manus and many others have put out thoughts on what this means.
Andrej Karpathy’s framing captures the gist of it:
Context engineering is the delicate art and science of filling the context window with just the right information for the next step.
Doing this right involves task descriptions and explanations, few shot examples, RAG, related (possibly multimodal) data, tools, state and history, compacting... Too little or of the wrong form and the LLM doesn't have the right context for optimal performance. Too much or too irrelevant and the LLM costs might go up and performance might come down.
Context engineering is just one small piece of an emerging thick layer of non-trivial software that coordinates individual LLM calls (and a lot more) into full LLM apps. The term "ChatGPT wrapper" is tired and really, really wrong.
Another tailwind is recent research from Chroma showing that increasing context lengths degrades performance.
Mastering context engineering is therefore key to reaching the goldilocks zone of performance and cost.
Betting on context engineering as a component of the emerging thick layer of software on top of LLMs is also a bet that is aligned with model improvements. Foundation model developers have been consistent throughout the last few years: build products that improve when models improve rather than addressing existing shortcomings, or risk being evaporated overnight. There have been several ‘red weddings’ over the last few years where companies died overnight following releases from the big labs - context engineering, on the other hand, aligns your product’s value creation with scaling laws.
Though this is a nascent concept in the AI Engineering community, some best practices are emerging, especially in designing agentic systems.
There’s a closely linked debate about multi-agent vs single-agent systems, but context engineering plays a key role in making agents reliable.
Manus, for example, considers the KV-cache hit rate ‘the single most important metric for a production-stage AI agent’. The reason for this is that in an agent loop the input-to-output ratio of tokens is huge (≈ 100 tokens of history for each token the model emits). The KV cache is a store of numerical tensors representing the model's processed understanding of tokens.
Let’s unpack what this means with an example, before linking this to other emerging parameters.
‘Research the latest developments in quantum computing and write a summary’.
The initial step that the agent takes would look like:
Step 0
System Prompt: "You are a research agent with access to web_search, file_read, and file_write tools..."
Tool Definitions: [detailed JSON schemas for each tool]
User Request: "Research quantum computing developments and write a summary"
KV Cache Status: Empty - this is all new
Step 1
Agent decides: "I need to search for recent quantum computing news"
Tool Result: [search results about IBM's quantum chip, Google's progress...]
Assistant: Let me search for more details about IBM's breakthrough.
<tool_call>web_search("IBM quantum chip 2024 Condor")</tool_call> ← ONLY NEW PART
What happens:
✅ Reuses cached KV for everything up to "Let me search..."
❌ Only computes new tokens: "Let me search for more details..."
10x faster than reprocessing everything!
You get the idea. The growing sequence stays in KV cache, whilst the only the newest tool call + result gets computed fresh.
This results in a huge cost saving via reduction in input tokens and much better latency. These gains are all material to the end-user experience and unit economics.
Additional best practices from Manus include:
The prefix cache has to stay the same throughout
Treat the tool list as immutable once the conversation starts, and instead mask the model’s logits so that only allowed actions have probability > 0. If you want to remove a tool, make the probability of using it 0 - see the calculator in example below
original_logits
= { "web_search": 2.3, "file_read": 1.8, "calculator": 1.2, # ← This tool should be forbidden "browser_": 0.4, "shell_": -0.1 }
masked_logits
= { "web_search": 2.3, "file_read": 1.8, "calculator": -∞, # ← Now 0% probability after softmax "browser_": 0.4, "shell_": -0.1 }
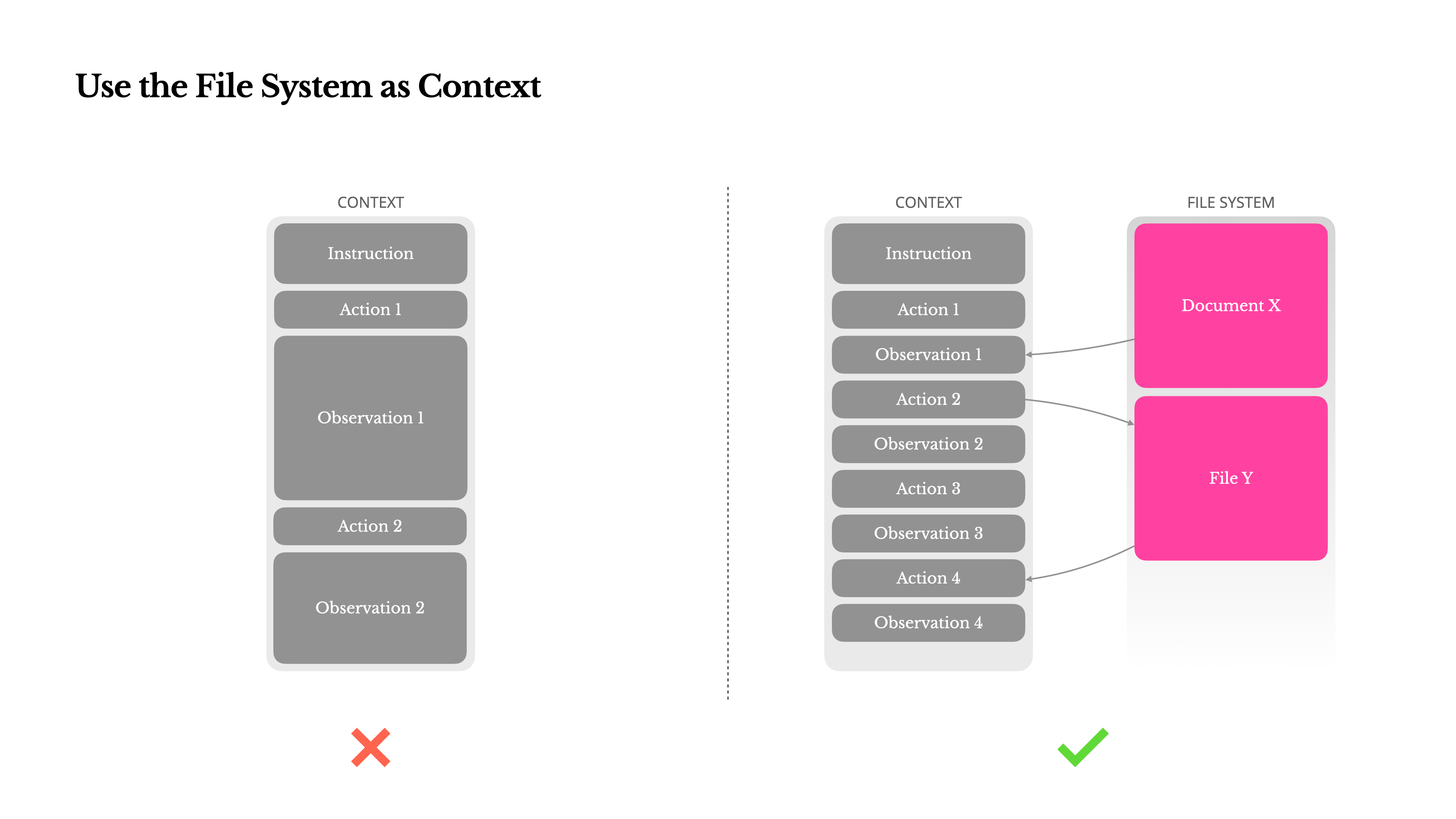
Use an external file system to store raw content, e.g. actual text, documents, web pages, and data that the agent is reading, in this case about quantum computing
Source: Manus
The external file system is Manus’ way of dealing with context rot:
That's why we treat the file system as the ultimate context in Manus: unlimited in size, persistent by nature, and directly operable by the agent itself. The model learns to write to and read from files on demand—using the file system not just as storage, but as structured, externalized memory.
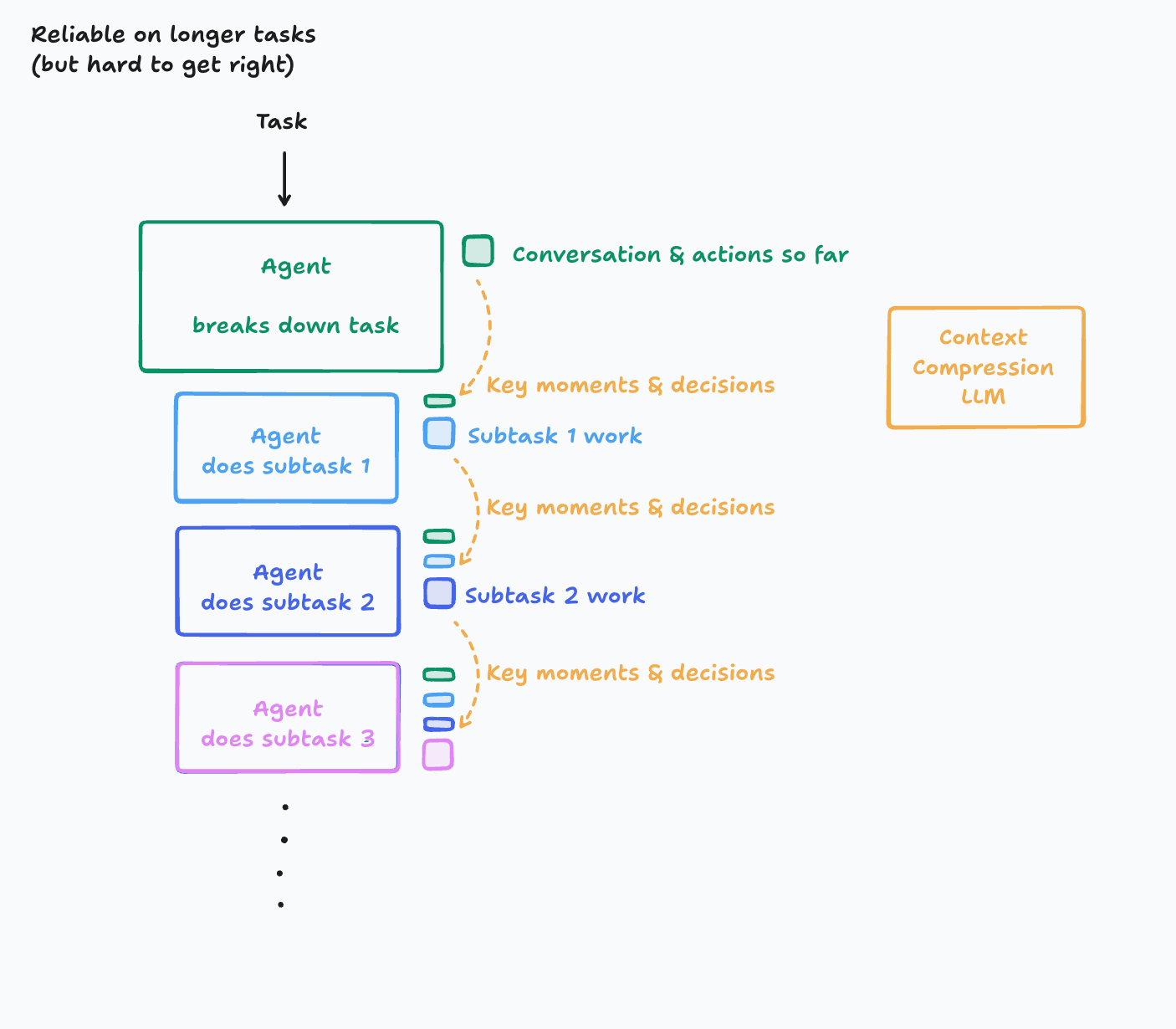
Cognition, advocates of single-agent systems, use special context compression LLMs:
In this world, we introduce a new LLM model whose key purpose is to compress a history of actions & conversation into key details, events, and decisions. This is hard to get right. It takes investment into figuring out what ends up being the key information and creating a system that is good at this. Depending on the domain, you might even consider fine-tuning a smaller model (this is in fact something we’ve done at Cognition).
Source: Cognition
You could imagine using compression models even when you’re storing KV caches, especially if the number of tool calls gets very large.
The goal is preserving state in a way that’s compute-efficient - this may sometimes call for pruning of context, too.
Source: Lance Martin
There are a lot of parameters here when you consider embeddings within RAG, internal and external tools, memory management and more - it’s an optimisation problem:
Context Engineering is the formal optimization problem of finding the ideal set of context-generating functions . . . that maximizes the expected quality of the LLM’s output.