

Browser Agents And The Agentic Web
Scaling from read to write-heavy tasks

Software Synthesis analyses the evolution of software companies in the age of AI - from how they're built and scaled, to how they go to market and create enduring value. You can reach me at akash@earlybird.com.
AI Sessions:
Following recent events on the MCP ecosystem and browser agents, next up:
July 24th: Evals
July 30th: MCP Part 2 with David Soria Parra
Last week we hosted a roundtable discussion on the current state of Browser Agents — it was a timely discussion as the business model of the internet evolves for the Agentic Web.

We started with a whistle-stop tour of the history of browser automation, from the early days of web automation in the 1990s to Selenium’s revolution for testing/QA, headless browsers in the 2010s, all the way to the present age of AI-native browser automation platforms.
Where headless browsers made automation at scale more computationally efficient, the new generation of vendors like Browserbase provide managed infrastructure that leverages LLMs to translate natural language instructions into Playwright/Puppeteer code, with a fallback policy to leverage Computer Vision models where elements of the page can’t be located.

This has significantly pushed out the Pareto frontier of browser agents, but the technology is still far from being fully autonomous in production.
The Web Bench tests demonstrated that although we’ve made a lot of progress in ‘read’ only tasks (tasks that require searching and extracting information), accuracy falls precipitously for more robust workflows that require writing, updating, deleting or file manipulation. The sharp increase in the number of steps for these types of tasks exposes the shortcomings of agents as of today (namely, memory).

The two failure modes are:
Agent capabilities (e.g. hallucination, session length, navigation)
Infrastructure (Captcha, login/auth, proxy)
With this set as the baseline for the discussion, we covered a lot of ground over the next hour.
Captcha handling
This is a fundamental challenge - it's an ongoing cat-and-mouse game that will continue evolving.
Automated solvers handle ~90% of common captchas (v1, v2), but v3 captchas and advanced protections (Cloudflare) remain challenging - more on that later
Human captcha services available (from cheaper labour pools) as fallback
IP whitelisting increasingly used - larger customers negotiate with platforms to whitelist automation IPs
Proxy hierarchy: Mobile proxies > residential proxies > datacenter proxies for avoiding detection
Technical Architecture
For approaches focusing on Document Object Manipulation (DOM):
Accessibility trees need aggressive pruning (200k→10k tokens)
Pruning techniques: Remove URLs, repeated elements, truncate long text, add reference numbers
Hierarchical fallback: Deterministic scripts → DOM-based → vision-based → OS-level interactions
Vision models used were either OpenAI or Anthropic’s
Evals
LLM-as-judge requires extensive human evaluations
Judge reliability: Evaluation accuracy depends entirely on judge quality - unreliable judges make metrics meaningless
Failure mode analysis: Write specific evals for observed failure patterns
Scale considerations: Need to run thousands of evaluations daily for production systems
Memory & Optimization:
Trajectory optimisation: Analyse successful runs to create optimised paths
Prompt engineering: Add specific instructions based on failure patterns
Real applications included property insurance quotes (Meshed) that reduced quoting time from one hour to 9 minutes, with browser agents effectively acting as junior brokers that invoke assistance from humans when they get stuck.
A general takeaway was that human-in-the-loop architectures are here to stay for the foreseeable future, given how high the financial losses can be from inaccuracy.
No one had seen browser agents actually pay for goods or services, as this would encumber the developer with PCI compliance.
That brings us to the announcements from Cloudflare last week.
Cloudflare’s positioning in the new internet economy
Advertising was the perfect business model for the human web, as Ben Thompson has written more eloquently than most.
The original web was the human web, and advertising was and is one of the best possible ways to monetize the only scarce resource in digital: human attention. The incentives all align: Users get to access a vastly larger amount of content and services because they are free. Content makers get to reach the largest possible audience because access is free. Advertisers have the opportunity to find customers they would have been never able to reach otherwise.
The Agentic Web breaks this business model as consumers shift towards answer engines or agents like ChatGPT who are themselves consuming publisher content to generate answers. Agents of course are indifferent to advertising, killing the ad-supported pipeline of new content.
With OpenAI, it's 750 times more difficult to get traffic than it was with the Google of old. With Anthropic, it's 30,000 times more difficult
The long-standing internet marketplace of users, advertisers and publishers is rapidly dying. It’s still unclear what will replace it.
Cloudflare, realising the advantageous position it’s in through its dominance of the CDN market, announced their vision for the Agentic Web:
Customers of Cloudflare are blocking AI crawlers by default unless they pay creators for their content
A new marketplace whereby publishers are rewarded for how much their content contributes to knowledge gaps, rather than traffic - creating the incentive for higher quality content
Pay-per-crawl ‘integrates with existing web infrastructure, leveraging HTTP status codes and established authentication mechanisms to create a framework for paid content access.’
While Cloudflare's announcement specifically targets AI training crawlers rather than task-automation agents, the technical reality is messier. The browser agent builders in our roundtable already navigate a complex landscape of anti-bot measures, suggesting that the line between 'legitimate automation' and 'unwanted crawling' exists more in intent than in technical implementation.
Whether Cloudflare's pay-per-crawl model remains limited to content scraping or expands to cover all automated web interactions will determine its true impact on the Agentic Web.
Data
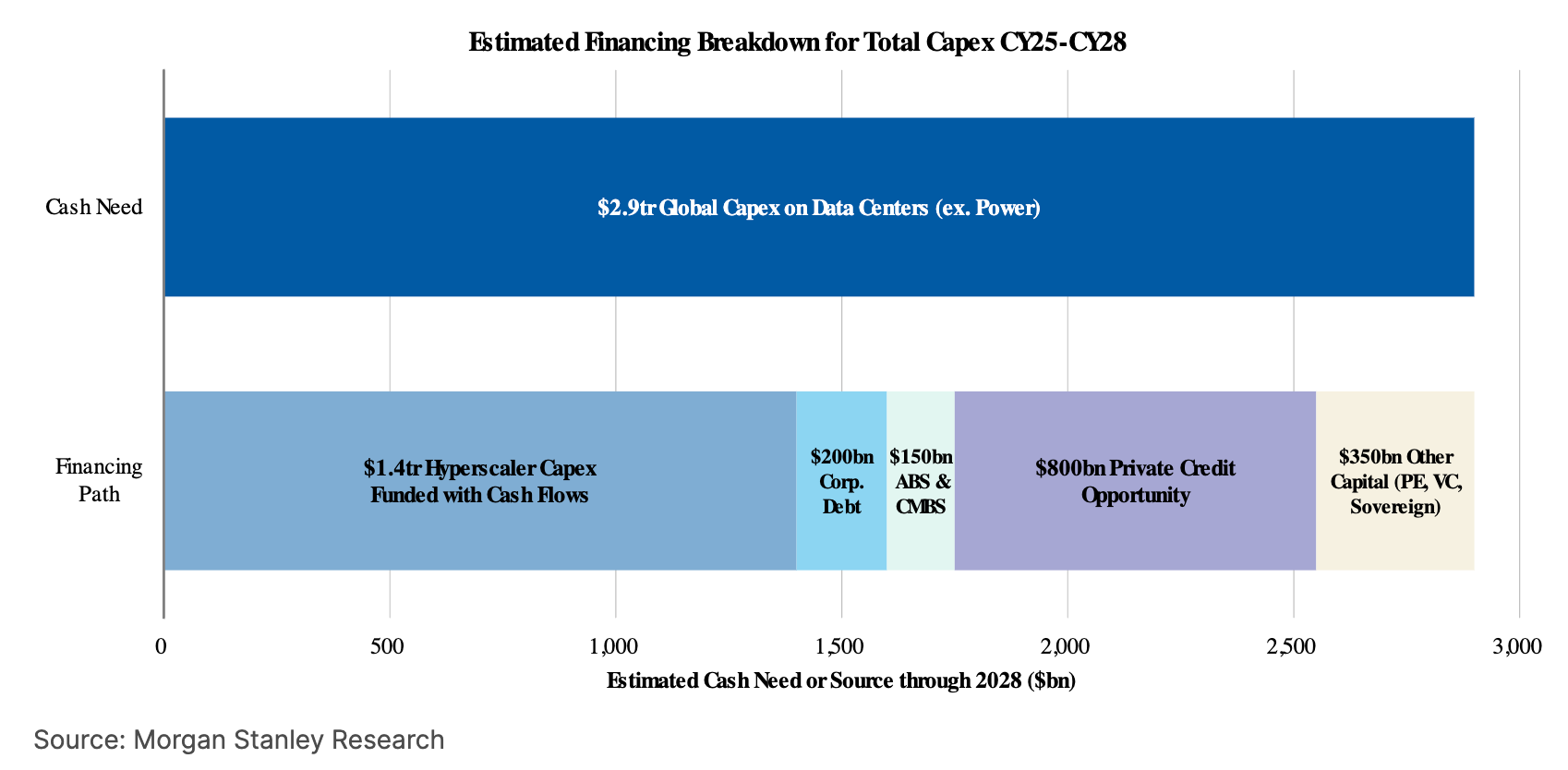
Will a new class of ‘Production Capitalists’ provide the capital needed for AI capex?
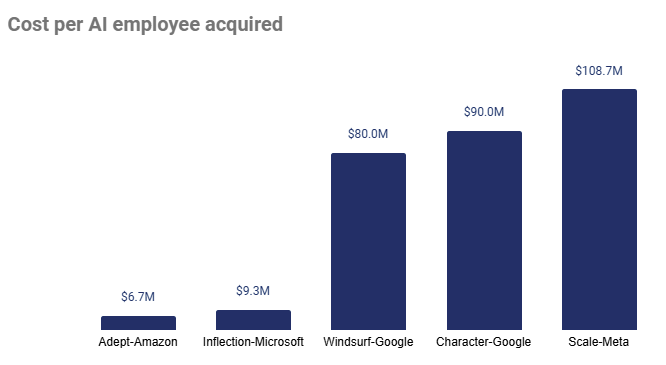
The AI talent wars are just beginning
Technology diffusion is accelerating

Increasing context lengths degrades performance - big implications for RAG

Reads
hypercapitalism and the AI talent wars
Kimi K2 and when "DeepSeek Moments" become normal
Have any feedback? Email me at akash@earlybird.com.
Tollbit was the one that pioneered the idea of fixing the robot.txt and scraping issue by creating a toll for agents. The founders saw the problem first hand when they were at Toast. Tollbit has been publishing quarterly reports tracking the evolution of agentic traffic. It started as learning traffic and now RAG is exploding. Cloudflare does have broader distribution and a bigger bullhorn than a small startup. So, they are getting the press. The problem I see with Cloudflare is that they are not the only CDN nor do they even have close to a plurality of the internet traffic. My guess is that the other CDNs such as Fastly and Akamai are not going to work with Cloudflare and will choose an independent marketplace provider.
Check it out:
https://tollbit.com/bots/25q1/