

AI Product Management and Evals with Aman Khan, Arize AI
Best Practices From Arize AI's Head of Product

Software Synthesis analyses the evolution of software companies in the age of AI - from how they're built and scaled, to how they go to market and create enduring value. You can reach me at akash@earlybird.com.
Gradient Descending Roundtables:
October 1st: Founder-Led Sales and Structuring Design Partnerships with James Allgrove
October 16th: The Data Platform for AI: Databricks’ Maria Zervou
Today’s post is an interview with Aman Khan, Head of Product at Arize AI.
Aman’s guide to evals remains one of the most popular posts on Lenny’s Newsletter, so I was of course delighted to dive deeper into a topic that’s top of mind for most founders building in AI today.

Aman is a Head of Product at Arize AI, an AI evaluation and development platform used by companies like Uber, Duolingo, Reddit, Instacart, and Booking.com.
At Arize, Aman helps teams launch and improve their AI agents and systems. He recently led a popular deeplearning.ai course on Evaluating AI Agents, and has been featured by Lenny’s Newsletter to cover AI Product Management and Evals a number of times. Prior to Arize, Aman led products at Spotify, Cruise and Apple.
The Three Types of AI Product Managers
How do you think about AI product management and where evals fit in?
I view there being three types of AI PMs.
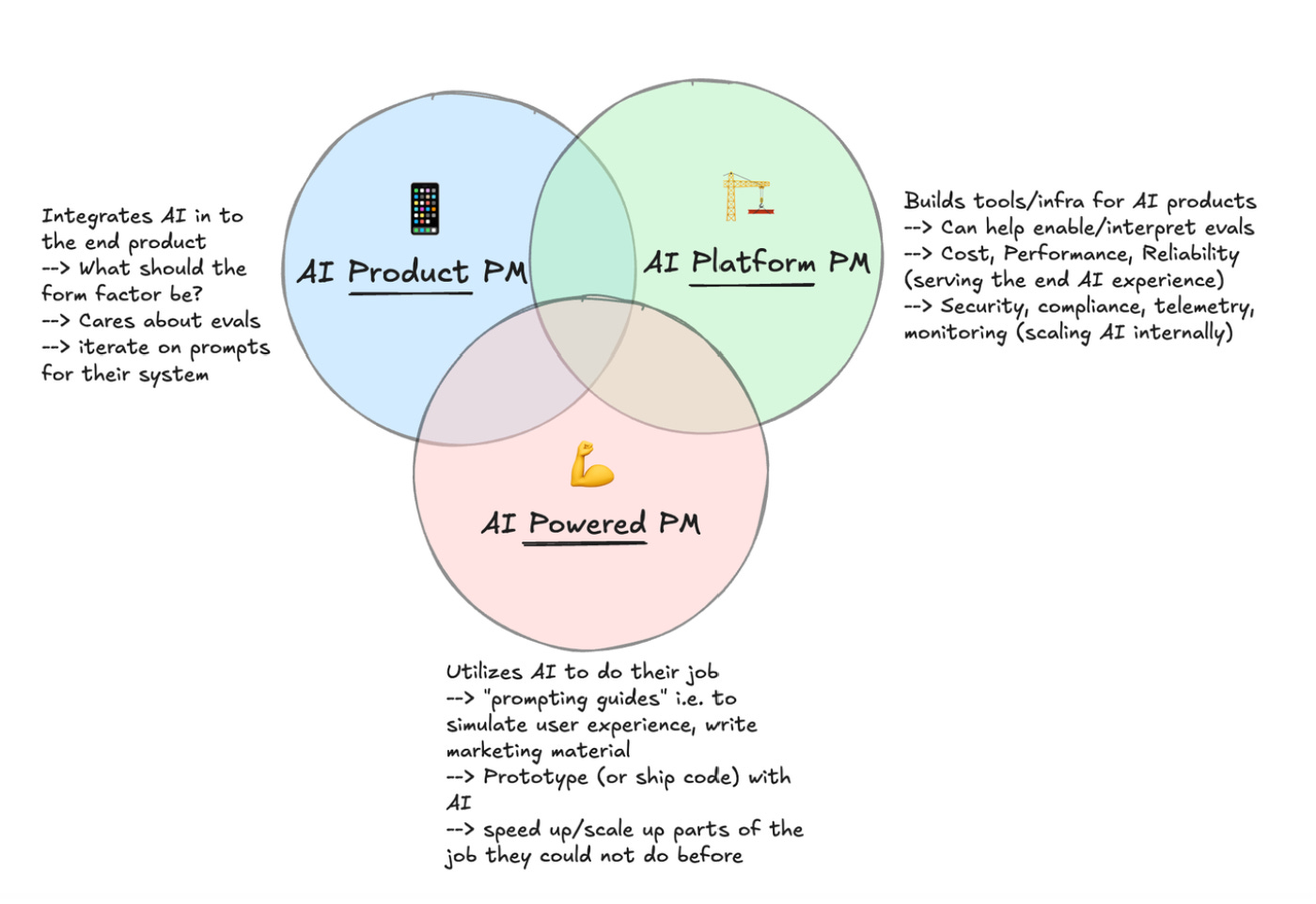
First, there’s AI-powered PMs - these are PMs using AI to actually build products themselves, like building prototypes or their own personal operating systems using tools like Claude Code. They’re using these products day in and day out.
Second, you have Platform PMs who think about the models themselves and the infrastructure to support those models at their company - security, scale, cost of the models.
Third, there’s AI product PMs, who think about how AI fits into the core product experience. Evals fit closest to this third category. This is the person ultimately responsible for what the end user experience looks like using their product, which just happens to have AI in it.
In that case, AI evals act as the metric - the functional requirement for “is this feature ready to ship?”, and when it’s out there, “are we actually hitting the goals we intended?”
The second type - the AI platform PM - seems like it’s not discussed enough. Maybe it’s seen as a core competency of DevOps engineers, but it seems so important now for uptime, cost, and margins.
Exactly. Picking the right model, picking the right sampling strategy - we’re trying to get to value with AI first, but pretty soon we’ll need to think more strategically about should we fine-tune these models or agents, which components of the model. You have to imagine these models are going to get more and more specific than the general-purpose intelligence model vendors provide right now. Tomorrow, if they launch more specific agents and models you can tune, how do you think about that? Even the way the LLM sits in your product - the parameters around that, sampling parameters, top-K, things like that.
The companies that are more sophisticated on this in the early days are just going to reap the benefits when it comes to quality and revenue.
Evals: Beyond Traditional QA
How do AI evals differ from traditional QA processes?
A lot of people ask me, “Isn’t this just what QA is supposed to do?” The short answer is yes, but the difference here is that QA isn’t just a binary pass or fail - it’s a subjective measure. That’s a big reason PMs are super valuable here, because subjectively determining what the end product experience should look and feel like is a big part of the job.
So working with QA and subject matter experts is part of the role of the AI PM when it comes to evals. We usually see AI engineers, subject matter experts, QA, and PMs all collaborating on the end eval that ships.
Are these still distinct roles in seed/Series A companies, or does QA fall on the team?
For seed/Series A, these are usually founders or early product developers. Unless you get to massive scale, your users and your team are essentially your QA. It ends up falling on the team at the end of the day.
LLM-As-A-Judge and Data Strategy
What’s evolved in your thinking about eval methodologies since your first piece with Lenny?
I think a lot of it still holds true. What’s been interesting is feedback on when to use what type of eval. A lot of people still jump to using LLM-as-a-judge first, but really what you want to do is look at your data, label it, and consider using code evaluators as well. It’s more of a holistic strategy - LLM-as-a-judge is one component of the evals you could be using. The most important thing is making sure you have all your data in the right place to evaluate it at all.
That came up in a session we did with Wulfie from OpenAI - they explained how LLM-as-a-judge should only be used after using human evals to get the judge model to be reliable.
That’s right. The job is to align the judge model to your judgment. You need to actually encode that first in your data before the judge can do a good job of that.
In-House vs. Marketplace Data Labeling
Given that many vertical AI companies are hiring domain practitioners as founding team members whilst some are opting for data labeling marketplaces, what should be the ratio of in-house labelling versus marketplace labour?
For companies like Mercor and Handshake - they pretty much just sell to foundation model labs right now.
There aren’t that many actual enterprises training models or sourcing out to these providers.
I think the quality of the agents is going to be determined by the quality of the data. As much as you can get realistic data from your end users and their experience, the better your iterations will be, because it’ll be more representative of real-world data.
If your labellers can provide high-quality data that’s as good as working with your customers, that’s great. But being able to scale that practice up yourself and encode that taxonomy is the right way to think about it. If you outsource that taxonomy and judgment, that’s a pretty core function of your AI product.
Look back at Scale and training models - so much of the quality of the models is determined by the quality of the training data. You’re effectively pushing out your feedback loop to find the long tail of problems.
The other takeaway from our evals discussions with OpenAI was getting as much production data and logs as possible so you can start labeling, which is always going to be better than synthetic data or data from these providers.
Yes, you can get multiple sources of data - synthetic, cheap data to augment your overall training set. We did that in the self-driving space too. But it’s not a substitute for real-world, high-quality data, so you’re going to be paying for that anyway. Most of the people we work with are logging their data to a platform to look at it and iterate on it every week with AI engineers.
What Top Companies Are Doing
What are you seeing the best companies do when it comes to evals (such as the likes of Sierra, Harvey and Decagon who have published their work on evals)? At Arize you have customers like Reddit, Instacart, Doordash.
The best companies have a strategy to look at really specific customer failure modes for specific customers. You’re taking your overall market, segmenting it down, and seeing what’s hard about that segment. You’re getting further and further into building specific datasets for customers.
What’s interesting is that very few companies are still fine-tuning. Very few have effective mechanisms to use real-world data for fine-tuning. The data is mostly used for prompt tuning, context engineering, A/B testing, and evaluation experimentation.
That means you can use these really specific customer datasets to know - like in Harvey’s case, if they solve a specific bug for DLA Piper generating contracts for agriculture tech companies, they’ll know they solved that problem because they have a test case dataset to represent it. That’s the right approach because it’s more white-glove, but you’re also more certain you’ve actually solved the problem versus trying to abstract it to a general category.
Companies like Sierra, Harvey, Decagon - they’re focusing on really specific, nuanced failure modes, finding more and more edge cases to solve for specific customers.
Annotation UIs and Workflow
How do you think about the UI for labelling, especially for domain experts who aren’t technical?
I see a lot of teams building annotation-specific UIs for their use cases. We at Arize offer a general-purpose one, but it really depends on the use case of what you’re trying to label and how you want to capture that feedback. For instance, with code, you probably want an execution environment to see if the code works.
We’ve thought more about what the data model should be so that your UI can be flexible on top of that. We have a UI that’s general purpose, but you can build your own UI using the same abstractions underneath - we expose APIs to pull down datasets and construct specific UIs around those same dataset objects.
Business Impact and Outcomes
How do evals ultimately tie back to business outcomes and top-line metrics?
The most obvious version is that you can now kick off many more experiments on improving problems you had. Step one of solving a problem is accepting that you have a problem. Being able to find and identify that problem using your own data - you can do that with evaluation. Then you use those same evals to know that you’ve solved the problem.
We have companies that run hundreds of experiments a day on different versions of their prompt, model, and context for various specific use cases. AI engineers now think of their job as less broadly thinking about the agent end-to-end and more specifically thinking about agent behaviours for specific customers or use cases.
It’s like self-driving - there was literally a PM responsible for unprotected left-hand turns, freeway driving, inclement weather at Waymo. Multiple PMs for different behaviours. I think you’ll see PMs and engineering teams oriented around agent behaviours rather than agent architectures.
That gets to the whole “95% of AI projects fail” narrative from the MIT report - it’s really about these specific behaviours that have failure modes.
Yes, even 95% feels high. I’d probably estimate even fewer experiments make their way into production, and that’s okay. It’s like asking, “I wrote this code, am I going to push it to prod or rewrite it?” Technology is very power-law driven. It’s more about that one use case - one out of 100 - that can drive maximal business value in a way you didn’t expect.
Can you automate 80% of the job versus 100% of it? That’s actually well worth the investment. It’s about levels of autonomy.
Check out prior interviews of Aman here with Peter Yang and Lenny Rachitsky.
Have any feedback? Email me at akash@earlybird.com.