

Agent Labs Are Product-First
Model Labs Are Product-Last

Software Synthesis analyses the evolution of software companies in the age of AI - from how they're built and scaled, to how they go to market and create enduring value. You can reach me at akash@earlybird.com.
Gradient Descending Roundtables in London:
October 16th: The Data Platform for AI: Databricks’ Chief AI Officer Maria Zervou
October 29th: Rubrics as Reward: RL Beyond Verifiable Domains with Scale AI
The debate around value accrual in AI has taken on a new framing: agent labs versus model labs.
Agent Labs vs Model Labs
In announcing that he’s joining Cognition, Swyx laid out the case for agent labs: models labs are product-last, whilst agent labs are product-first.
From 2015 (when OpenAI was founded) to 2025, the right place to work was clearly at model labs, seeing through the 3 paradigms of pretraining, scaling, and reasoning. With OpenAI now at $500B valuation, burning up to $45B a year, and Anthropic now at $200B, with GDM and Xai and the Chinese labs and more and more scaling up with competitive models, model diversity is a real thing, providing a new optimization surface area for app-layer builders.
Agent labs ship product first, and then work their way down as they get data, revenue and conviction and deep understanding of their problem domain.
Model labs create frontier models, Agent Labs adapt them to domains that they don’t fully solve yet: The future is here, but it is not evenly distributed. In interestingly opposite ways, Agent Labs either serve to “distribute” the frontier to markets that it hasn’t yet reached, or they serve to “pull forward” the future (by either burning vc money ahead of the 1000x/1.5yrs price drop per unit intelligence that is happening broadly in AI, or pricing your Agent properly so you can get more out of current models using tricks like self-consistency to simulate having a future model.
The difference between ”unreasonably effective” “LLM in a Loop” oversimplification and agents like Devin and Cascade is the “remaining 10%” that developers chronically underestimate.
Cursor and Cognition are perhaps the two leading agent labs, valued at $20bn and $10bn respectively despite relying on large foundation models from OpenAI Anthropic and others, all whilst Claude Code reached $500m run-rate revenue within 4 months of GA.
The rough playbook for how agent labs could differentiate was becoming clearer as early as last December, when we first discussed vertical integration in AI.
As my friend Alex Mackenzie has written, where developers could previously attribute more than half of Cursor’s value to the underlying third-party models, the company is well funded to flip that ratio by developing their own models.
The sequence they did it in, though, matters. They have developer mindshare.
We can see the chessboard that the agent labs and model labs are playing on with much higher resolution now. Dylan Patel of SemiAnalysis made the case for agent labs recently in the context of Cursor:
Does Anthropic have all the power? The common view is yes from a lot of people. But then it’s, well, Anthropic only makes the model that’s generating the code.
There’s a lot more in this system. Cursor gets all of the data (how do they interact with this), they get all of the users. Anthropic doesn’t get that. They get prompt, they send a response.
Now they have Claude Code which is taking share and it’s very different than Cursor but they get prompt response and then Cursor is training embedding models on your code database.
There’s actually multiple models that I’ve made. I’ve made the embedding model, I’ve made the autocomplete model. I can switch the Anthropic model to the OpenAI model whenever I want to. I’m only using Anthropic model because it’s the best one. Oh, and because I have all this data, maybe I can train a model not for everything better than you, but for the segment better than you.
This playbook does raise legitimate concerns around Business-Model-Product-Fit if agent labs are dependent on model labs for market share:
Cursor’s users expect the best coding performance, which is currently delivered by the frontier labs. That pins Cursor’s COGS to OpenAI/Anthropic price cards. Cursor doesn’t control two critical dials:
Model performance frontier (what users demand).
Model input/output pricing (what Cursor pays).
If Cursor steps down to cheaper, weaker models, the users who care about performance will notice and churn; those who can tolerate weaker models can get them cheaper elsewhere. If it stays at the frontier while keeping prices flat, the variable, real cost to service their heaviest users will explode. In an effort to combat this, Cursor has been forced to raise prices and institute usage caps leading to user outrage and churn.
Any time “unlimited” shows up in a variable-cost business, PMF becomes a permanently open question:
Are users here for the product, or for the subsidy?
Would they still use as much—or at all—at true marginal cost?
Until Cursor prices consumption in proportion to cost, it cannot know.
Is that really what’s happening, though?
Satya Nadella once said of Microsoft’s relationship with OpenAI:
We have the people, we have the compute, we have the data, we have everything. We are below them, above them, around them.
Cursor, Cognition and other agent labs are all working towards the same goal of mitigating platform dependency on any single model lab by building below, above and around them.
A usual retort at this point in the debate is to argue that it’d be foolish to bet against continued improvement from the model labs.
Well, it’s one thing to be long on continued model advancements and a totally different thing to concede everything to superintelligence, as Cognition CEO Scott Wu shared with John Collison:
I think the biggest thing I would just say here is, software engineering in the real world is so messy, and there’s all sorts of these things that come up. And I think in practice, most disciplines look like this, and I would say the same thing about law or medicine and so on. And so while the general intelligence will continue to get smarter and smarter, I think there is still a lot of work to do in making something, both on the capability side really good for your particular use cases, but also in actually going and delivering a product experience and bringing that to customers, of how that actually happens in the real world.
I think you could consider us short superintelligence.
Scott hits on the key argument for agent labs:
I think there’s a real difference where, as soon as you go from hardware to… Obviously foundation model training is its whole own can of worms, and very much the DNA of the company is finding exceptionally strong researchers, giving them as many GPUs as you can afford to give them, and setting up a culture that kind of orients around that.
And then the application layer, I would say, is really focused… I would say obviously it has a lot of the elements of research as well, but I think in particular is really, really focused on just figuring out how to make one use case work. For us, for example, the only thing that we care about is building the future of software engineering. And maybe one thing I would call out is, people often talk about AI code abstractly, in a vacuum. I think there are a lot of companies that think about code in the foundation model layer or things like that. I think we uniquely really think about software engineering and all of the messiness that that comes with, and all the product interface and all of the delivery and the usage model, and of course a lot of these particular capabilities that come with that. So, I think there’s a real… Everyone has their own DNA and everyone has their own things that they do best.
But I think that, in practice, what we’ve seen in the space is naturally there is a lot of contextual knowledge, there’s a lot of industry details, there’s a lot of… And so as we were saying, going and doing some Angular migration or doing some… It’s not to say that these things can’t get better. In fact, I think they will continue to get much better. But I think that the way that we make models better and better at them is by giving it the right data of… How good can you be at Angular migrations if you’ve never seen Angular, and you’ve never done an Angular migration yourself? And there’s this kind of a cap on that.
Agent labs have the product surface area that captures the most valuable data needed for RL.
Training below, above, and around model labs
Fine-tuning and RL are being productised and abstracted for agent labs to capitalise on their data and distribution advantages.
Just recently Thinking Machine Labs’ Tinker was the latest abstraction for fine-tuning, whilst OpenPipe (acquired by CoreWeave) announced a serverless RL product.
These abstractions pave the way for agent labs to start as API consumers of model labs → capture traces/evals → train narrow models (embeddings, autocomplete, router, policy) before attempting larger training runs with open-source models.
Data visibility is the moat
Model labs see prompts/responses, not the full interaction system; agent labs see repo context, file diffs, tool runs, CI results, tests, revert events, acceptance, and retention. This enables them to train embeddings, autocomplete, and other local models—and to swap base LLMs at will.
This all comes down to agent labs being product-first, whereas model labs are product-last. This confers the right to:
Design rewardable product surfaces. Being intentional in how they design their products to capture reward signals, e.g., “tests pass,” “ticket closed,” “SLA met,” “demo booked.” Treat reward design like growth loops.
Operationalise Serverless RL/SFT: push small, frequent runs tied to weekly releases; log why reward moved
Exploit parameter-efficient updates to base models
Keep base-model substitutability real: multi-model routing + thin local models (embeddings/autocomplete/policy) so you can re-align quickly if pricing/policies shift.
Close the loop: invest in evals + telemetry that connect user actions → reward signals. Tie this to improving COGS by reducing spend on upstream tokens over time to find true BMPF
Alongside infra developments, research on RL environment engineering is evolving fast — Scale AI’s Rubrics as Rewards pushes RL beyond verifiable domains (math/coding) by turning expert checklists (“rubrics”) into structured reward signals.
As the infra and research on RL/fine-tuning progress, value will accrue to those agent labs that own the end user, the environment they work in, and reward signals.
AI Applications… Agent Labs?
Swyx shied away from defining agent labs in his post, but every AI application startup is grappling with the same challenge of building thickness on top of model labs. The direction is clear: all applications are becoming agentic and completing work.
Model labs are allocating researchers and GPUs towards scaling laws, novel architectures, tool calling, memory and various other primitives.
Agent labs focus on taking these horizontal primitives and verticalising them for distinct use cases, which presents its own set of challenges.
In that sense, startups are also labs. These labs use the scientific method to run experiments across a range of AI engineering dimensions. The resulting agents deliver on the promise of AI across verticals.
Data
Data and infrastructure vendors underpinning AI are the earliest beneficiaries of the platform shift, along with security. Incumbent applications remain under pressure.
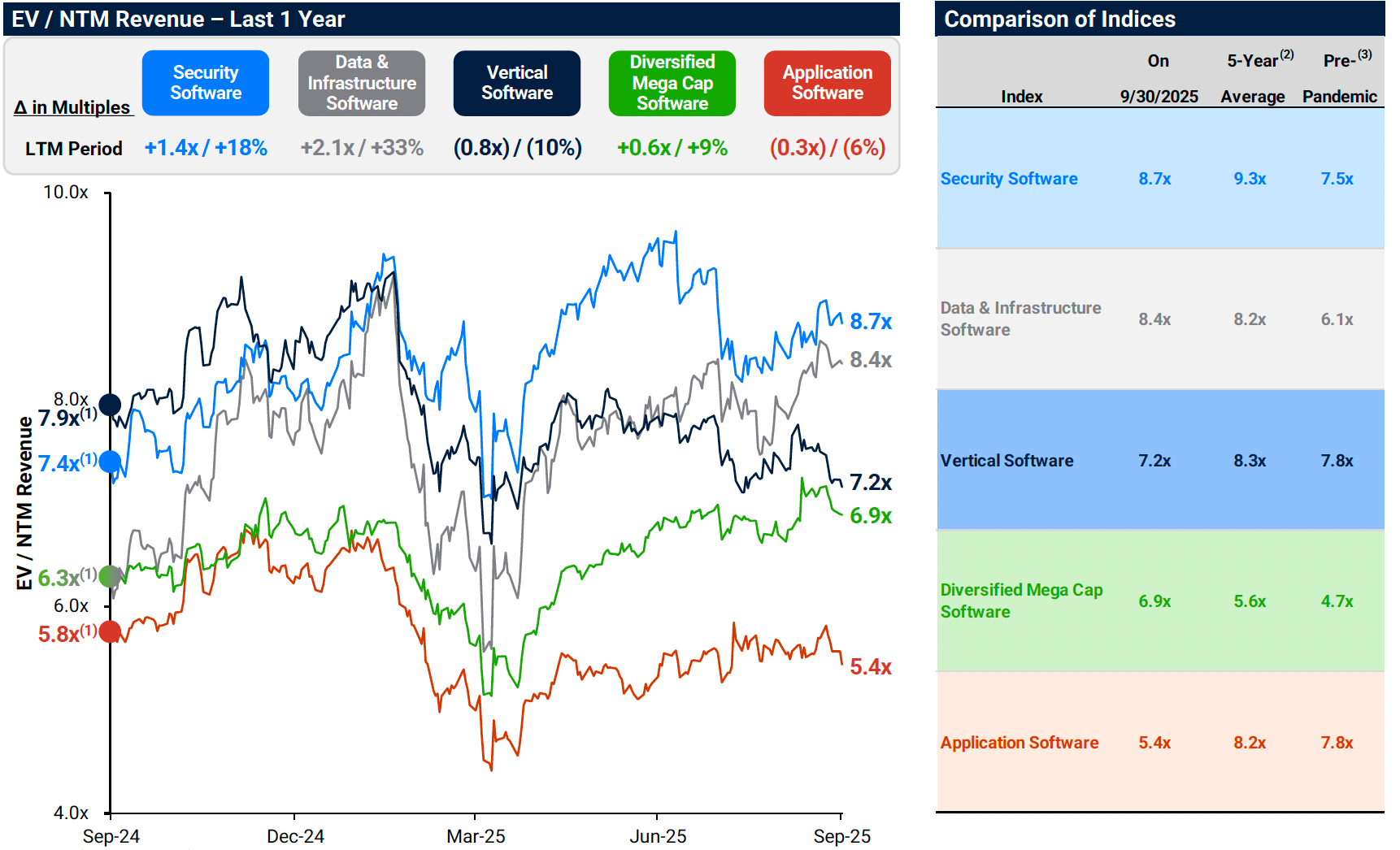
ChatGPT cohorts show increased engagement as capabilities improved
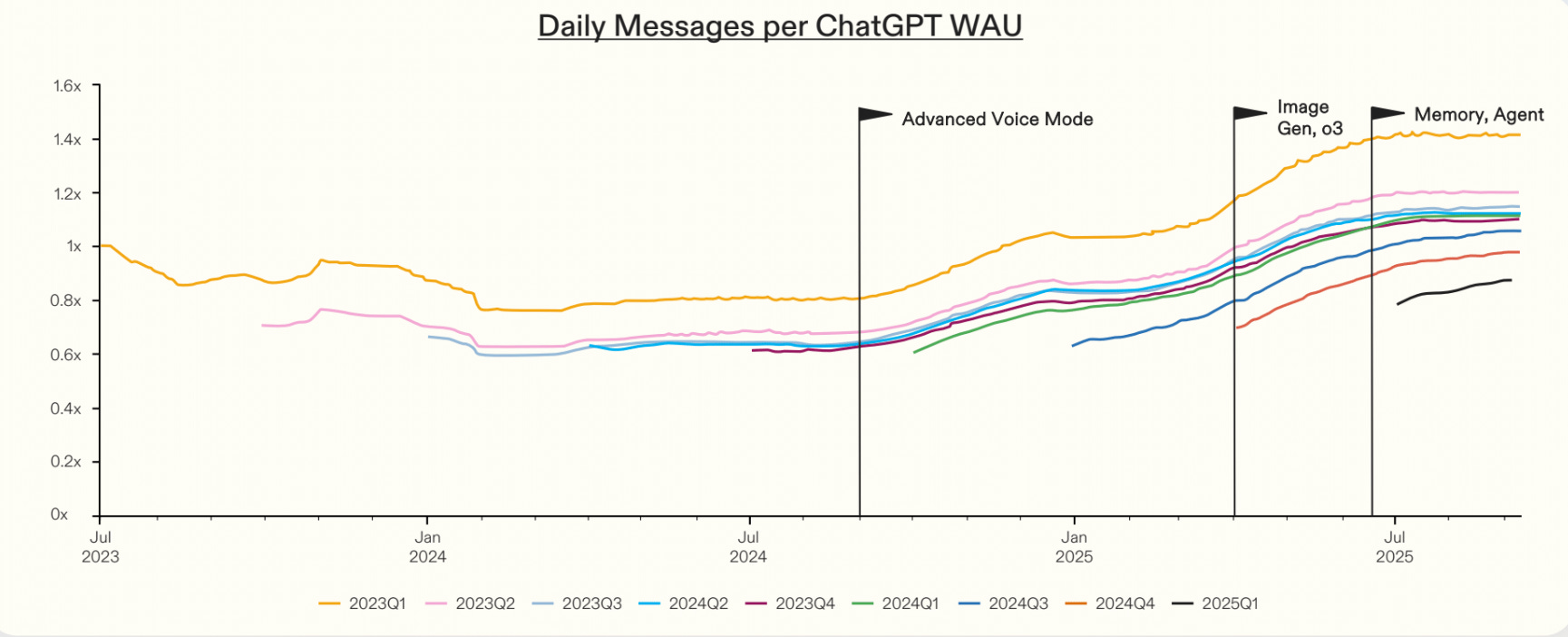
Gemini now leads in Computer Use models
Reading
The stablecoin duopoly is ending
Failing to Understand the Exponential, Again
Have any feedback? Email me at akash@earlybird.com.